Modelos ARMA: generalizaciones y resumen.¶
Modelos ARIMA¶
En algunos casos, la serie de datos \(x_t\) no es estacionaria, y no alcanza con “sacarle el trend” para volverla estacionaria.
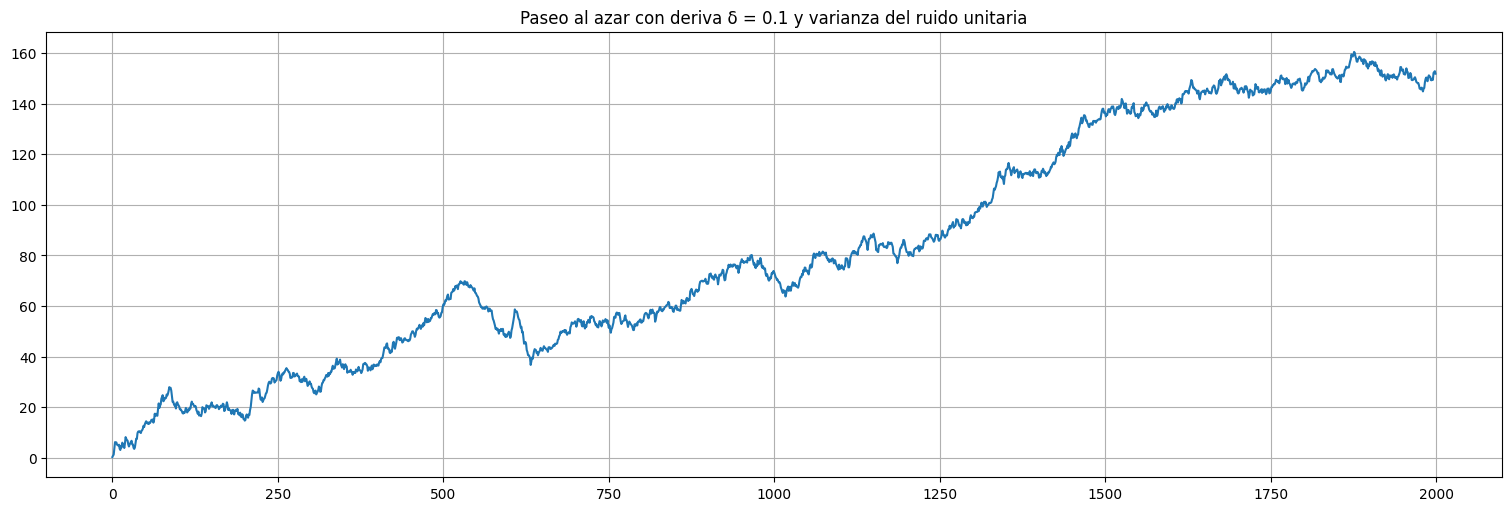
Ejemplo: consideremos el paseo al azar:¶
con \(w_t\) ruido blanco de varianza \(\sigma^2_w\). Este proceso no es estacionario (tiene una tendencia \(\delta t\) de pendiente \(\delta\)).
## Simulación de un paseo al azar con deriva
delta = 0.1
w = np.random.normal(loc=0,scale=1,size=2000)
x = np.cumsum(w+delta)
x = pd.Series(x)
x.plot()
plt.title(f"Paseo al azar con deriva δ = {delta} y varianza del ruido unitaria");
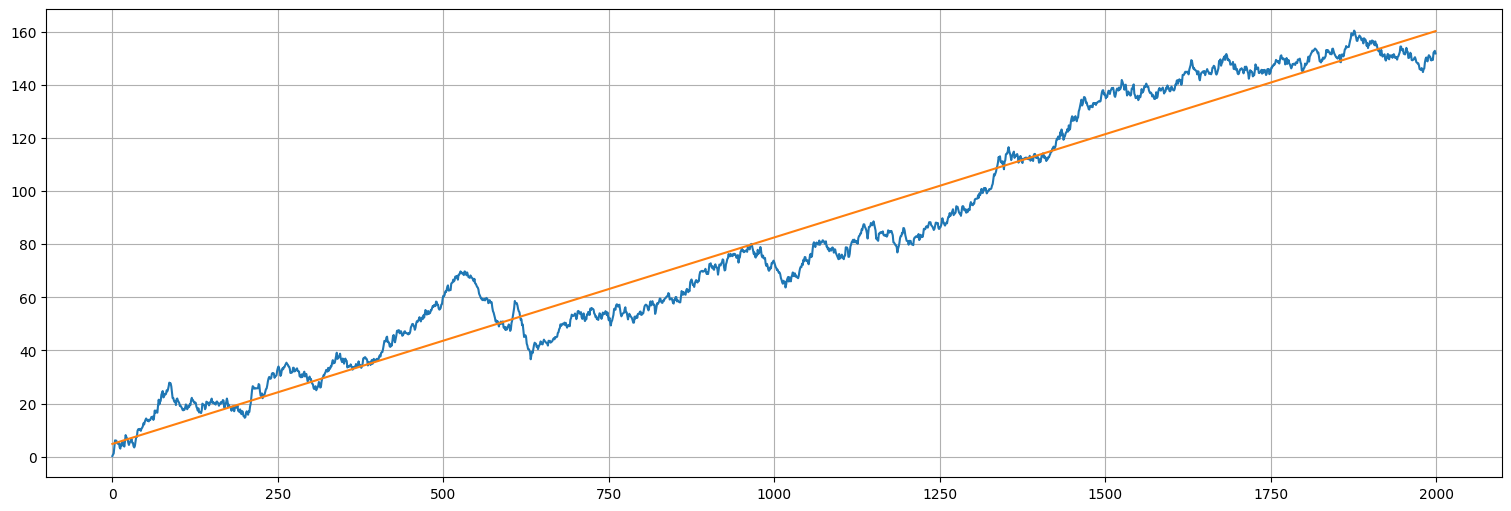
Idea 1: Ajuste lineal¶
con \(w_t\) ruido blanco gaussiano.
from statsmodels.formula.api import ols
fit = ols("x~x.index.values", data=x).fit()
fit.summary()
| Dep. Variable: | x | R-squared: | 0.956 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.956 |
| Method: | Least Squares | F-statistic: | 4.346e+04 |
| Date: | Mon, 19 May 2025 | Prob (F-statistic): | 0.00 |
| Time: | 16:23:27 | Log-Likelihood: | -7366.5 |
| No. Observations: | 2000 | AIC: | 1.474e+04 |
| Df Residuals: | 1998 | BIC: | 1.475e+04 |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 4.8141 | 0.430 | 11.183 | 0.000 | 3.970 | 5.658 |
| x.index.values | 0.0777 | 0.000 | 208.476 | 0.000 | 0.077 | 0.078 |
| Omnibus: | 226.571 | Durbin-Watson: | 0.011 |
|---|---|---|---|
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 63.079 |
| Skew: | 0.048 | Prob(JB): | 2.01e-14 |
| Kurtosis: | 2.135 | Cond. No. | 2.31e+03 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 2.31e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
x.plot()
fit.fittedvalues.plot();
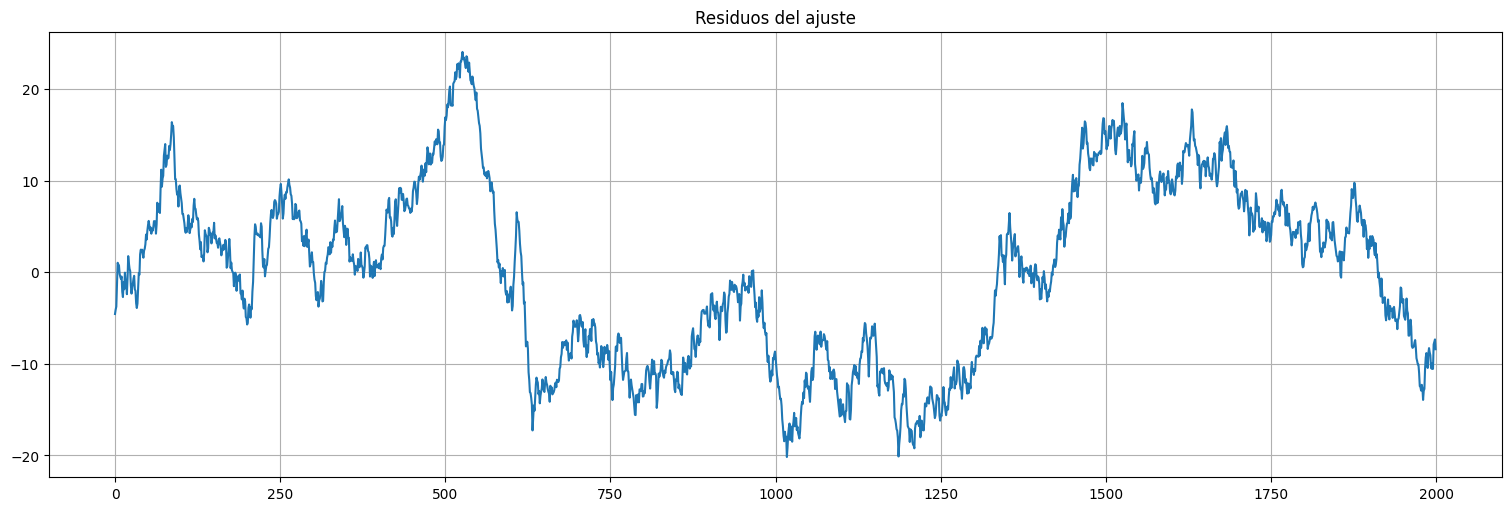
Miremos los residuos del ajuste:
fit.resid.plot();
plt.title("Residuos del ajuste");
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plot_acf(fit.resid, bartlett_confint=False);
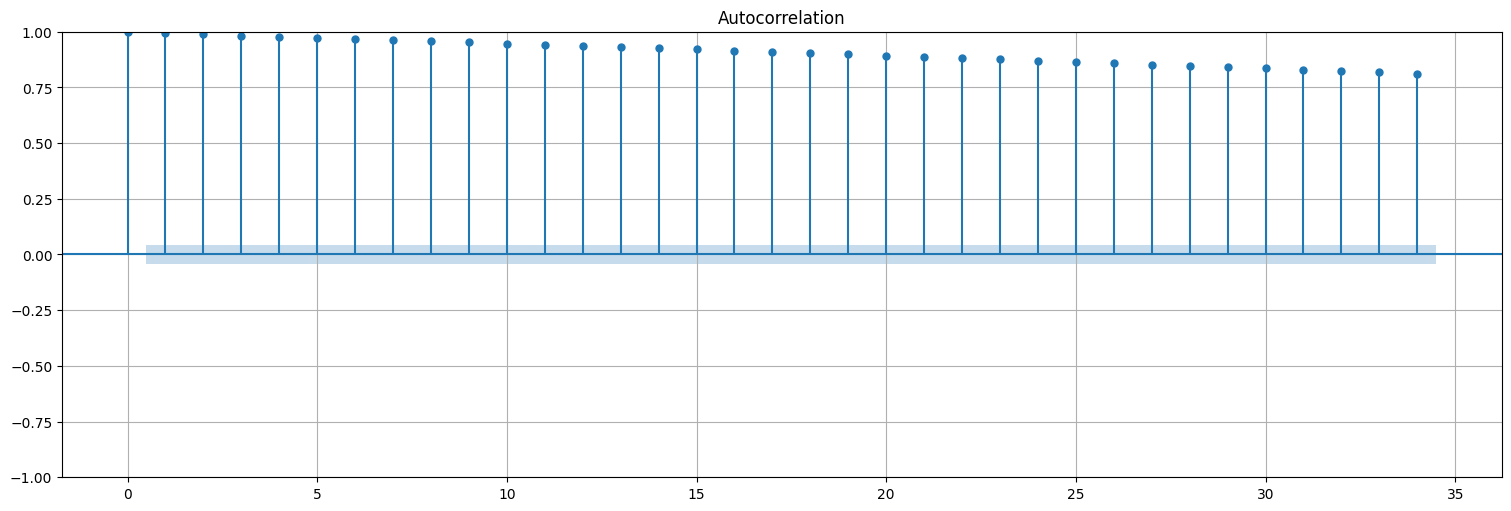
Mejor idea: tomar diferencias de la serie.¶
Sea:
Es decir, al tomar diferencia la serie se vuelve ruido blanco puro en este caso (estacionario), a menos de la media.
y = x.diff().dropna() #diferencio la serie en pandas directamente. El dropna es para eliminar el primer valor que no tengo.
y.plot()
plt.title(f"Serie de diferencias, media = {np.mean(y)}");
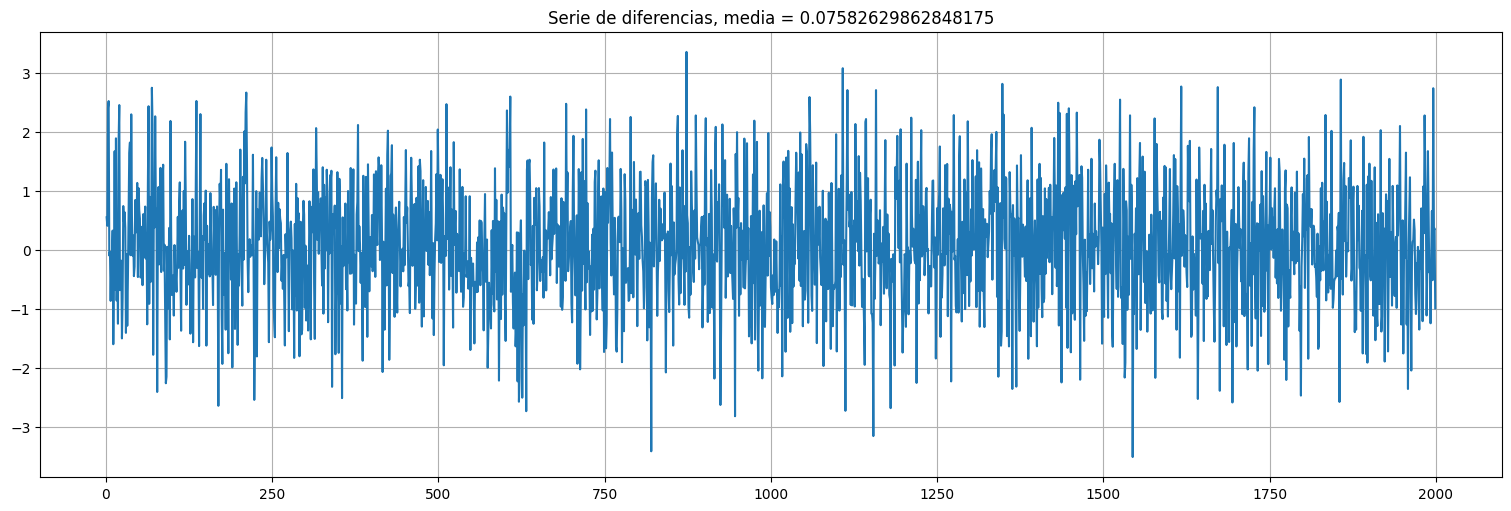
Miremos ahora la autocorrelación de las diferencias:
plot_acf(y,bartlett_confint=False);
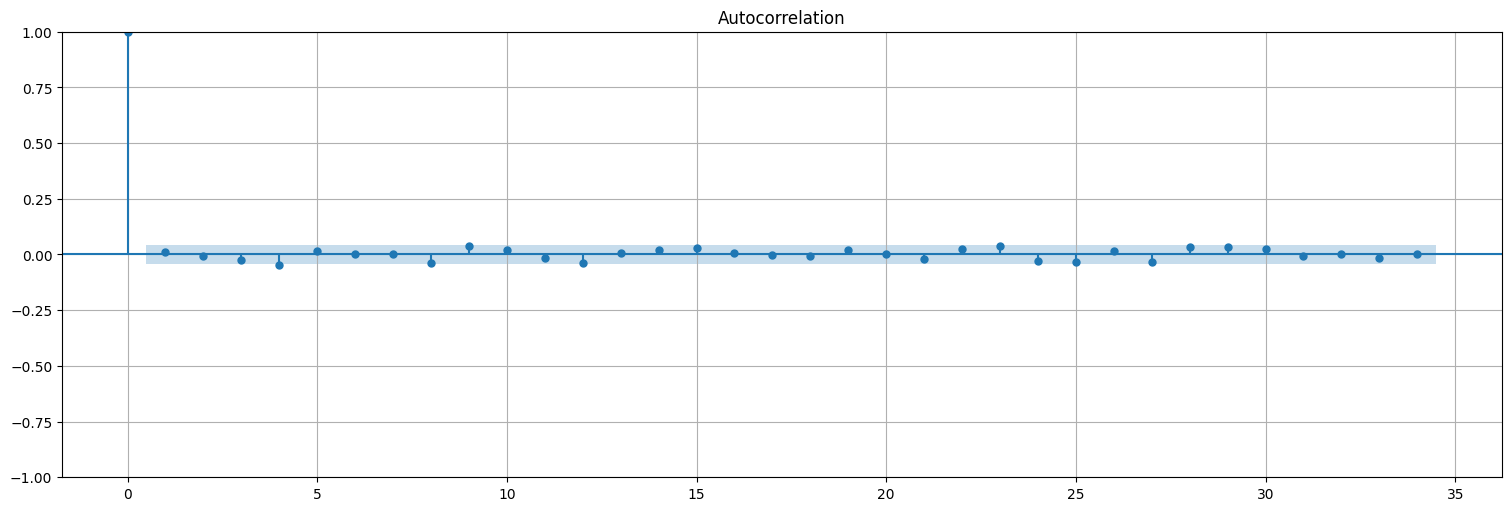
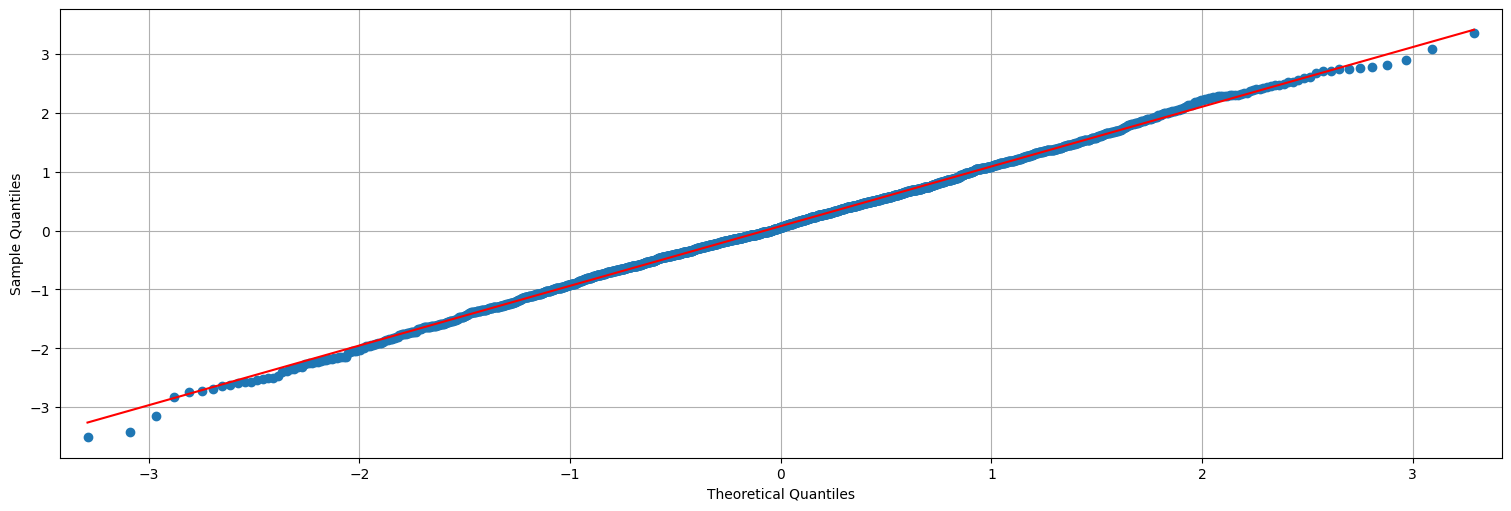
Y también chequeamos si son aproximadamente Gaussianos:
from statsmodels.graphics.api import qqplot
qqplot(y,line='s');
Ejemplo no tan ejemplo…¶
En data/eur_vs_usd.csv esta la variación diaria del precio del euro frente al del dólar. Analicemos esta serie.
eur = pd.read_csv("../data/eur_vs_usd.csv").dropna()
eur = pd.Series(eur["US dollar/Euro (EXR.D.USD.EUR.SP00.A)"].values,index=eur["DATE"])
eur.plot();
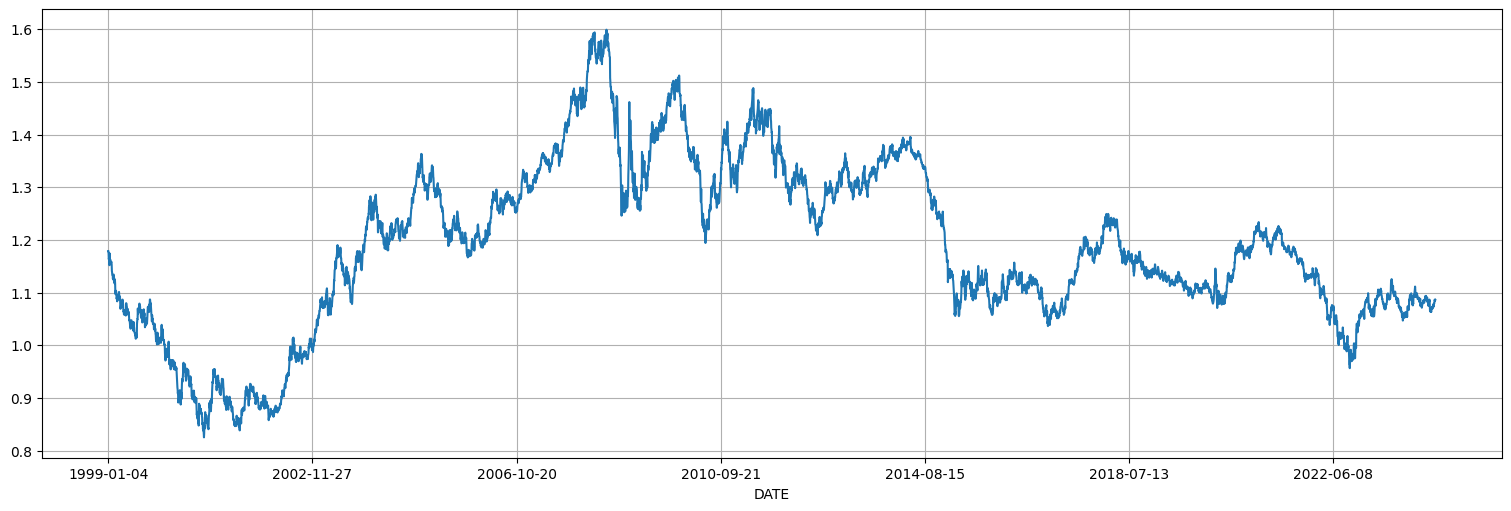
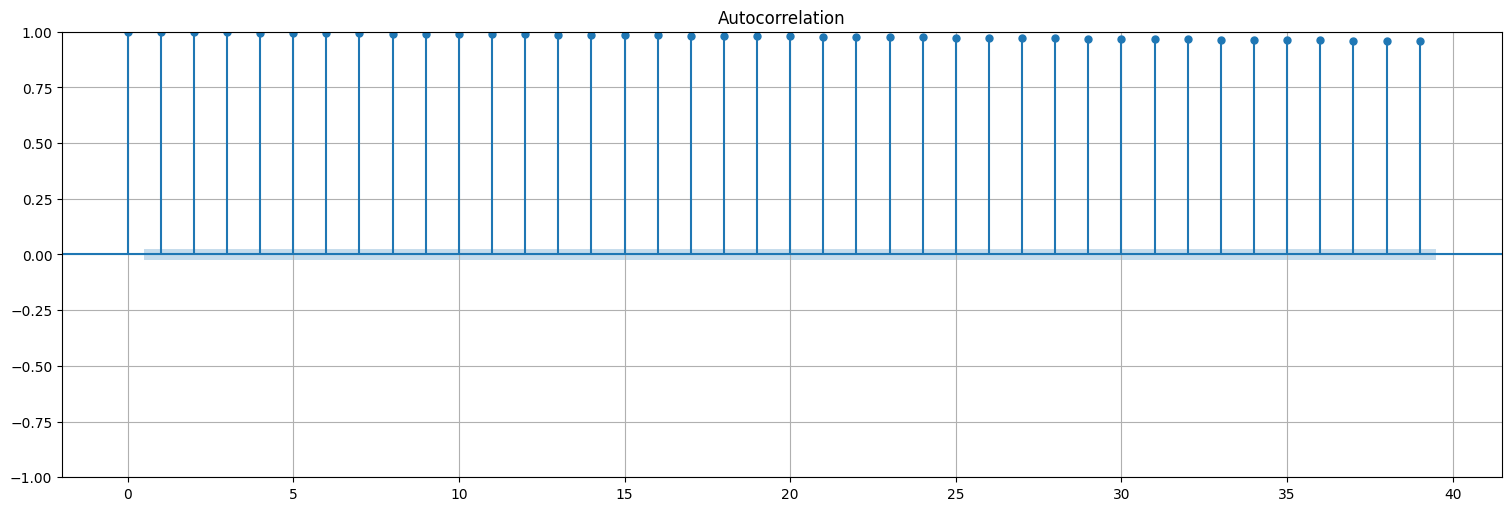
Miremos la autocorrelación y vemos que no es estacionaria.
plot_acf(eur, bartlett_confint=False);
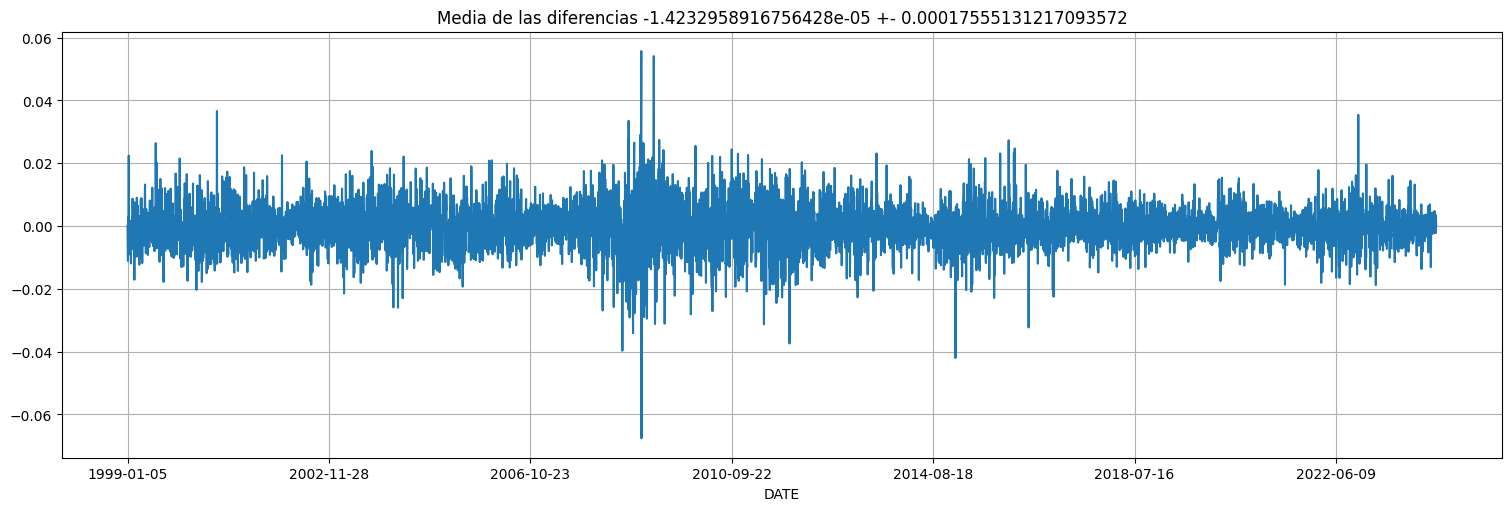
Probemos ahora el truco de tomar diferencias:
y = eur.diff().dropna()
y.plot();
plt.title(f"Media de las diferencias {np.mean(y)} +- {2*np.std(y)/np.sqrt(y.size)}");
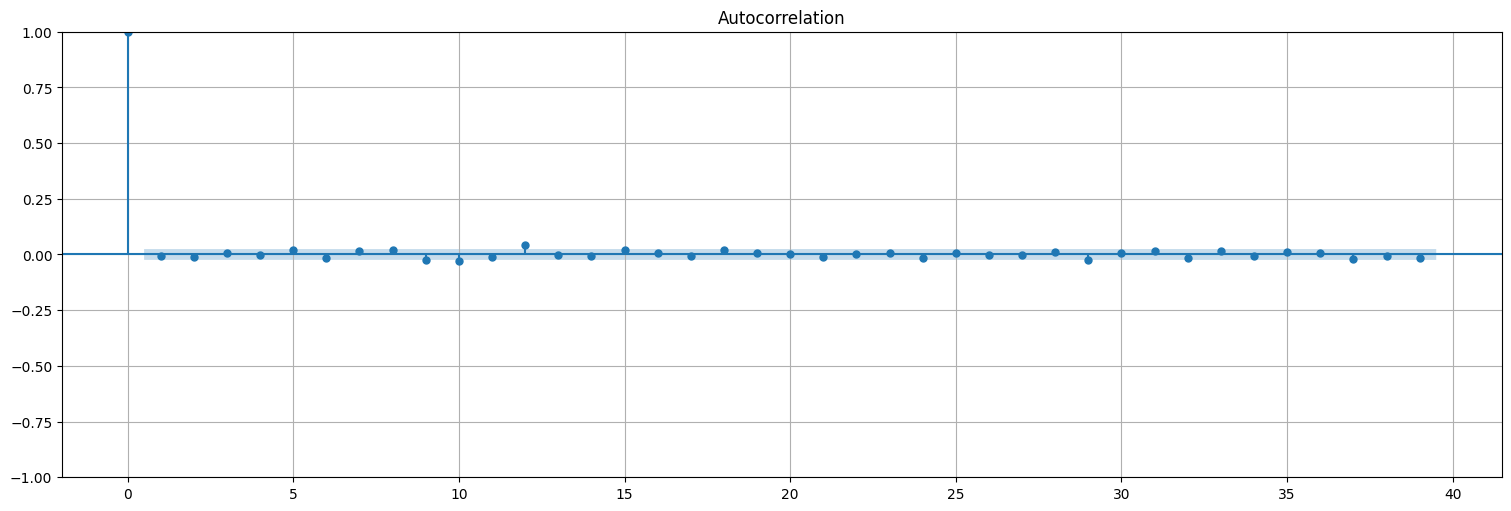
Miremos la autocorrelación de la serie diferenciada, se asemeja a ruido blanco:
plot_acf(y);
Sin embargo, la serie no es estacionaria. Presenta momentos de mayor y menor varianza (volatilidad). En particular la distribución se aleja de una Gaussiana.
qqplot(y,line='s');
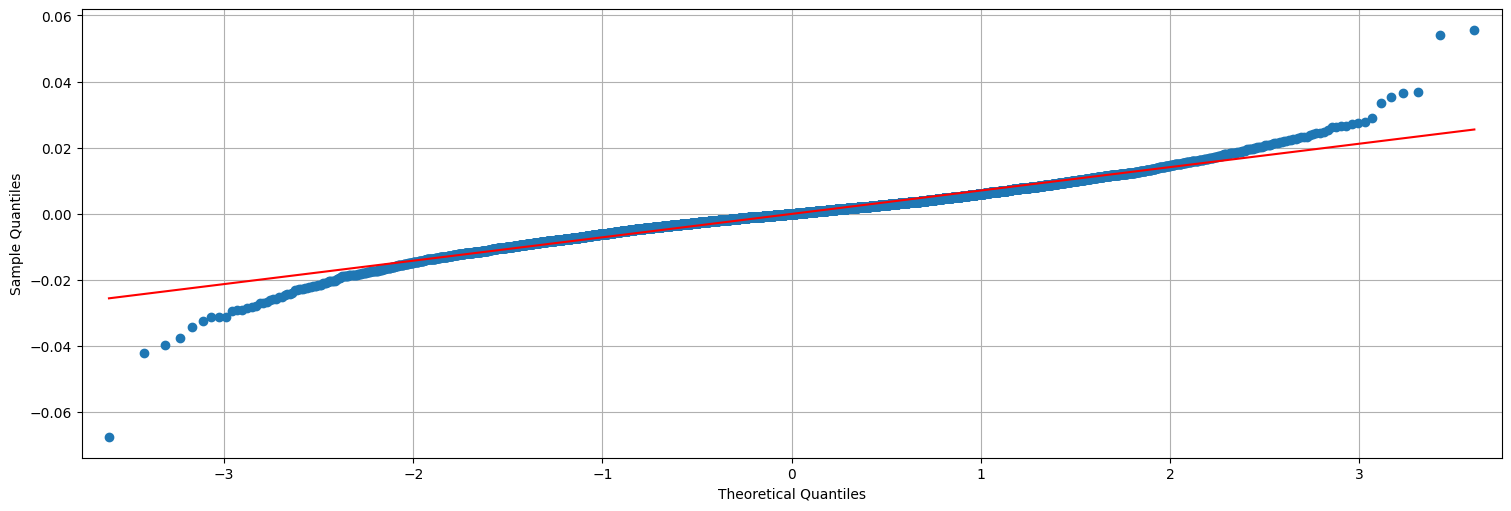
Interpretación:
A corto plazo, la serie se comporta como un paseo al azar sin deriva (la media de las diferencias da \(0\)).
Pero a largo plazo, la serie presenta heterocedasticidad, palabra difícil para decir varianza variable.
Ejemplo: serie con trend lineal.¶
Supongamos que: $\(x_t = \mu_t + y_t\)$
con \(\mu_t = \beta_0 + \beta_1 t\) e \(y_t\) estacionario. Entonces (introduciendo el operador \(\nabla\) para las diferencias):
Es decir, la nueva serie “diferenciada” tiene una media \(\beta_1\) que sale de la pendiente de la recta de tendencia y una componente estacionaria compuesta por las diferencias de la serie \(y\) anterior.
Nota: en general, si el “trend” es un polinomio de grado \(n\), diferenciar \(n\) veces elimina el trend.
Modelo ARIMA¶
Esto lleva a la definición del modelo \(ARIMA(p,d,q)\) genérico.
Definición: decimos que una serie \(x_t\) es \(ARIMA(p,d,q)\) si: $\(y_t = \nabla^d x_t\)$
es un \(ARMA(p,q)\). Es decir, si diferenciar la serie \(d\) veces produce un proceso \(ARMA\). El nuevo parámetro \(d\) es la cantidad de veces a diferenciar.
Ajuste de modelos ARIMA¶
Para el ajuste de modelos ARIMA, simplemente podemos reutilizar todo lo visto para \(ARMA(p,q)\) una vez que sabemos cuántas veces hay que diferenciar (\(d\)). O sea, lo único nuevo es “descubrir” el \(d\) necesario para que la serie quede estacionaria. Típicamente no se usa \(d\) muy grande.
Ejemplo¶
Consideremos que tenemos una serie \(x_t\) de la forma:
con \(y_t\) tal que \(z_t = \nabla y_t\) es autorregresivo de orden \(1\) y coeficiente \(\phi\).
from statsmodels.tsa.api import arma_generate_sample
n=500
beta0 = 50
beta1 = 3
phi=0.9
z = arma_generate_sample([1,-phi],[1],n)
y = np.cumsum(z) #Esto genera la serie y a partir de la x, acumulando que es la operación contraria a diferenciar.
x = beta0+beta1*np.arange(0,n)+y
x = pd.Series(x)
x.plot();
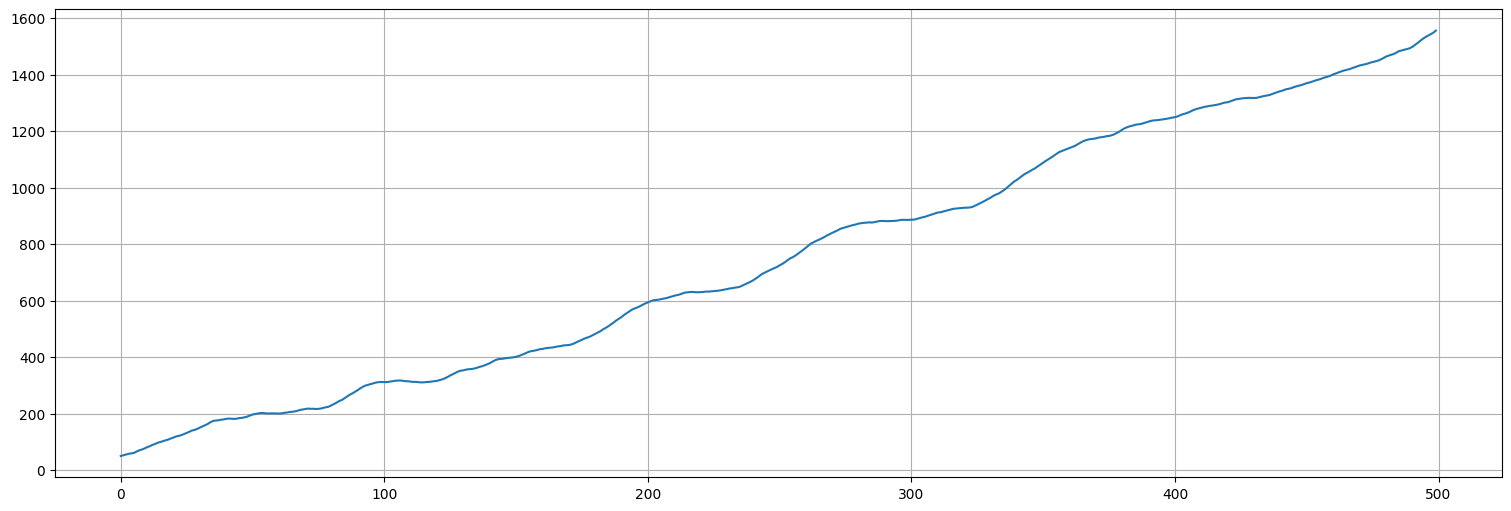
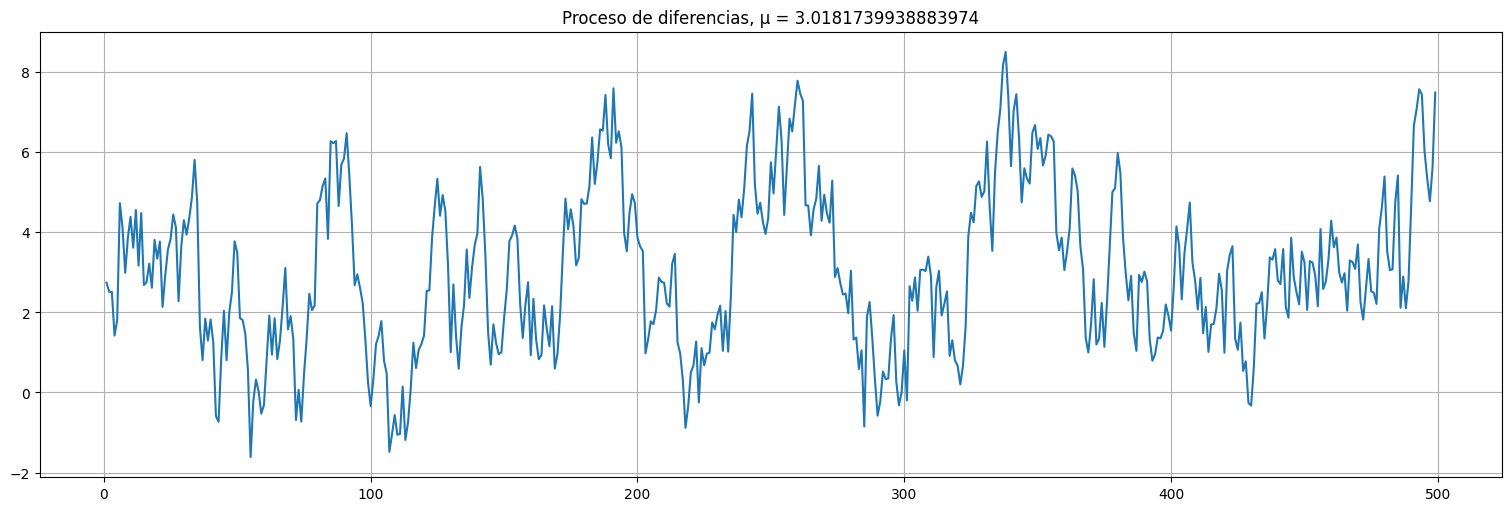
Analicemos ahora el proceso \(\nabla x\), es decir las diferencias.
#Al diferenciar recupero z pero con media beta1.
dx = x.diff().dropna()
dx.plot()
plt.title(f"Proceso de diferencias, μ = {np.mean(dx)}");
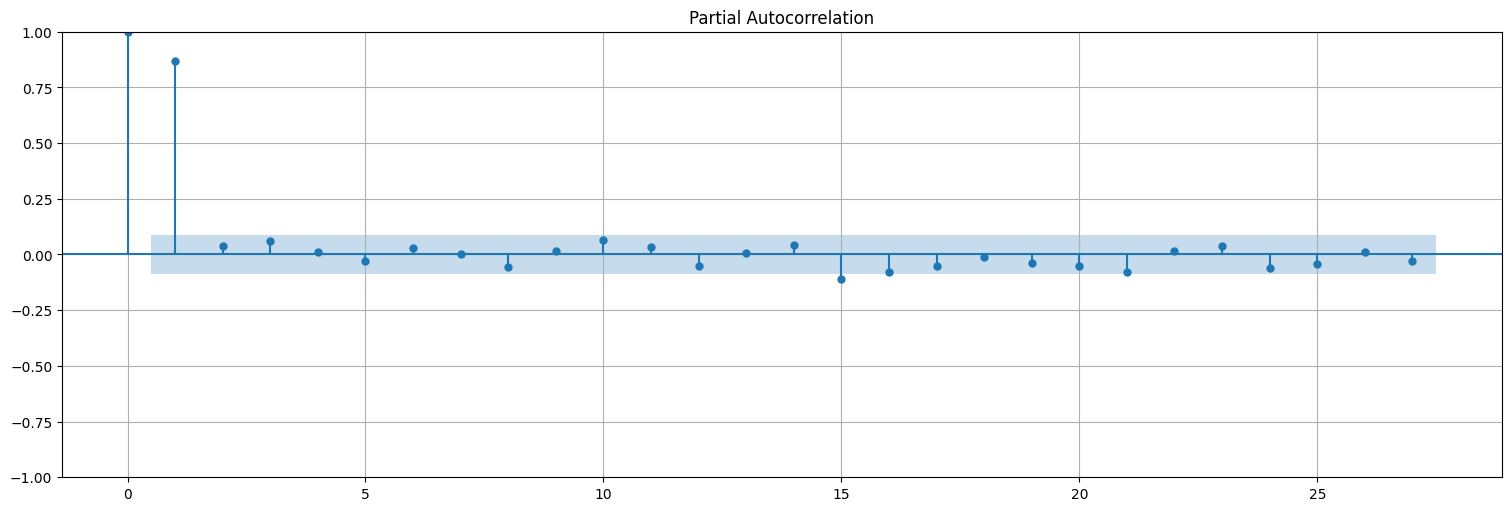
#las correlaciones confirman la estacionariedad (parece un AR(1) en este caso)
plot_pacf(dx);
##Ajusto directo un ARIMA a la serie x usando statsplots
## el parámetro trend="t" permite que la serie diferenciada conserve el drift
## la media del resultado de diferenciar
from statsmodels.tsa.api import ARIMA
fit = ARIMA(x,order=(1,1,0), trend="t").fit()
fit.summary()
| Dep. Variable: | y | No. Observations: | 500 |
|---|---|---|---|
| Model: | ARIMA(1, 1, 0) | Log Likelihood | -700.929 |
| Date: | Mon, 19 May 2025 | AIC | 1407.859 |
| Time: | 16:24:43 | BIC | 1420.497 |
| Sample: | 0 | HQIC | 1412.818 |
| - 500 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| x1 | 3.0749 | 0.353 | 8.721 | 0.000 | 2.384 | 3.766 |
| ar.L1 | 0.8740 | 0.023 | 38.628 | 0.000 | 0.830 | 0.918 |
| sigma2 | 0.9690 | 0.064 | 15.148 | 0.000 | 0.844 | 1.094 |
| Ljung-Box (L1) (Q): | 0.33 | Jarque-Bera (JB): | 2.49 |
|---|---|---|---|
| Prob(Q): | 0.57 | Prob(JB): | 0.29 |
| Heteroskedasticity (H): | 0.95 | Skew: | -0.16 |
| Prob(H) (two-sided): | 0.73 | Kurtosis: | 2.87 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Analicemos los residuos del ajuste:
res = fit.resid.iloc[1:] #saco el primer residuo porque no tiene sentido luego de diferenciar
res.plot();
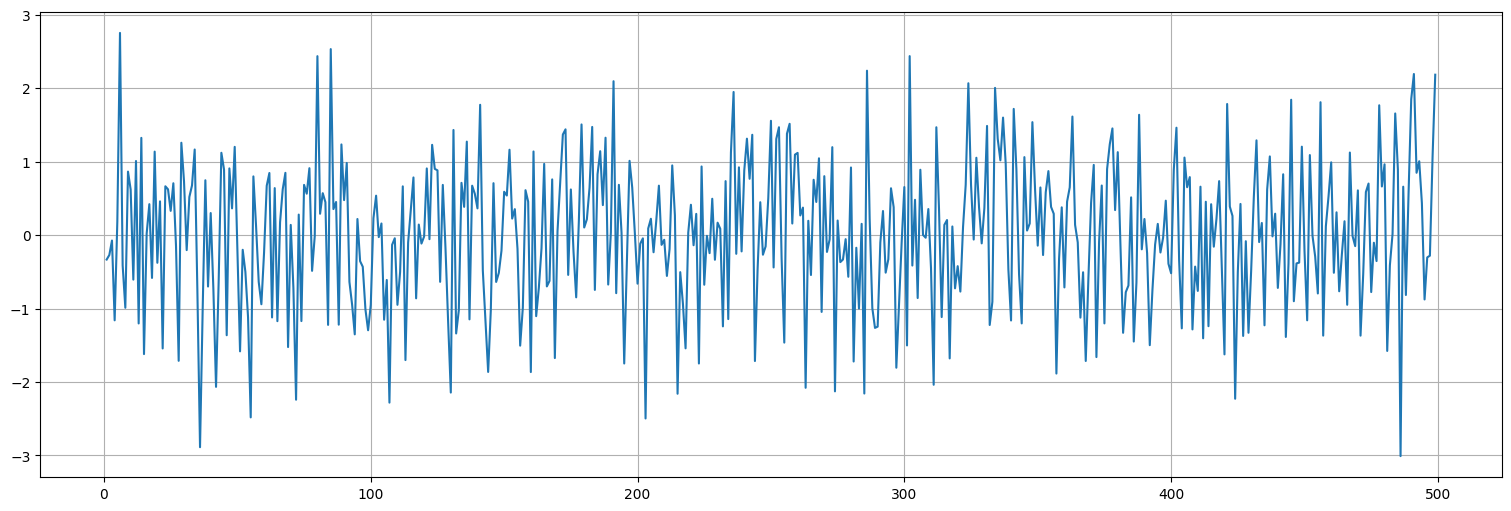
plot_acf(res, bartlett_confint=False);
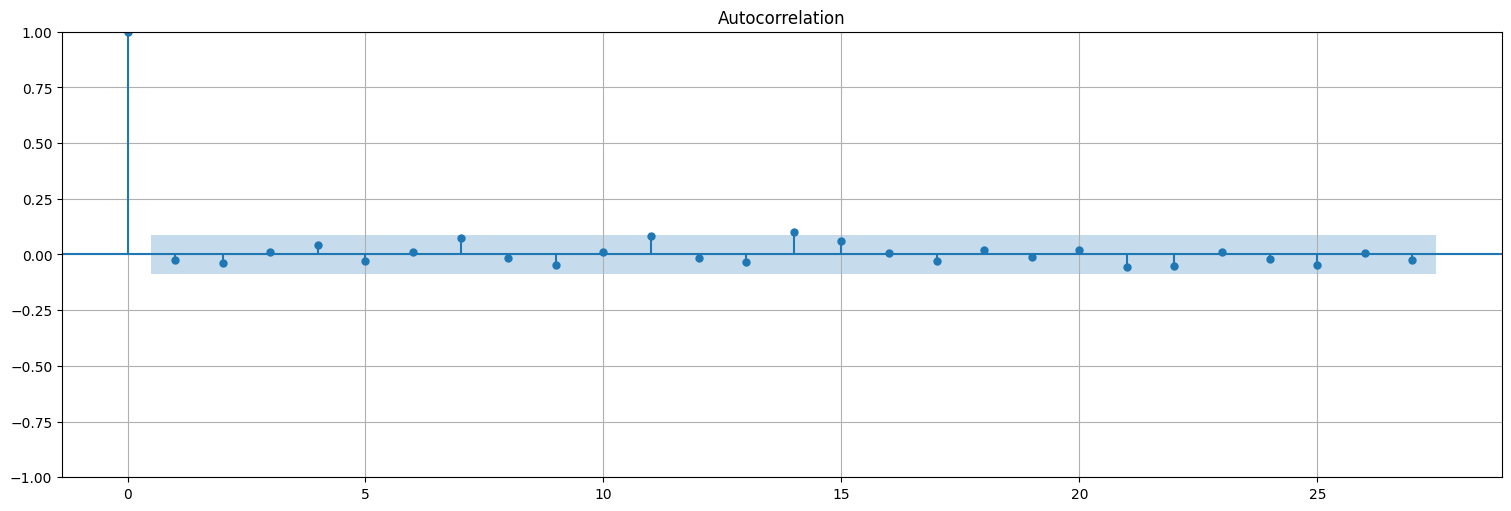
qqplot(res,line="s");
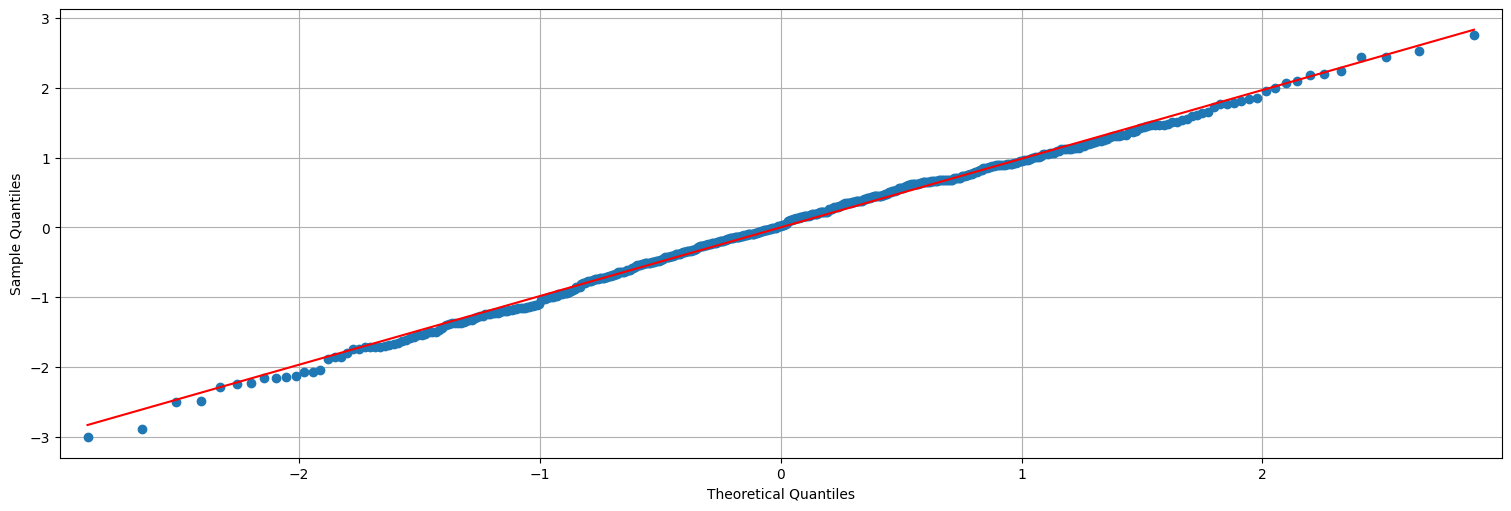
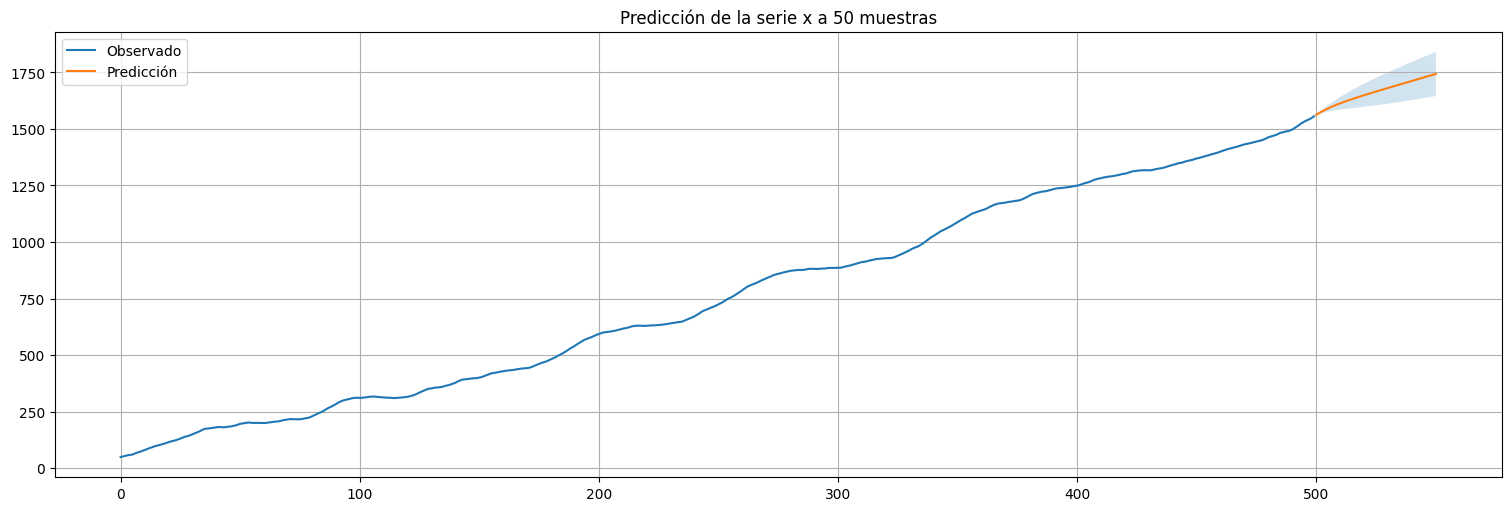
#Usamos el modelo ajustado para predecir a futuro
h = 50 #horizonte de predicción
predicciones = fit.get_prediction(start=x.size,end=x.size+h)
xhat = predicciones.predicted_mean
confint = predicciones.conf_int(alpha=0.05) #alpha es la confianza del intervalo
x.plot()
xhat.plot()
plt.legend(["Observado","Predicción"])
plt.fill_between(xhat.index,confint["lower y"], confint["upper y"], alpha=0.2);
plt.title(f"Predicción de la serie x a {h} muestras");
Resumen: ARMA, ARIMA, ajuste, predicción.¶
Con todo lo visto, hemos construido una especie de receta (debida a Box-Jenkins) para trabajar con este tipo de modelos, a saber:
Graficar los datos
Trasnformar los datos (por ejemplo, transformación logarítmica, o detrend o ambos, diferenciación).
Identificar los órdenes de dependencia (acf, pacf).
Estimación de parámetros (fit, básicamente mínimos cuadrados o máxima verosimilitud).
Diagnóstico (análisis de residuos por ejemplo).
Elección del modelo (criterios de información tipo AIC, evitar overfitting, etc.)
Predicción en base a estimadores lineales calculados recursivamente e intervalos de confianza.
Ejemplo completo: la serie GNP¶
Esta serie contiene el Producto Nacional Bruto (GNP) de Estados Unidos medido trimestralmente desde 1947 a 2002.
gnp = astsa.gnp
gnp.plot();
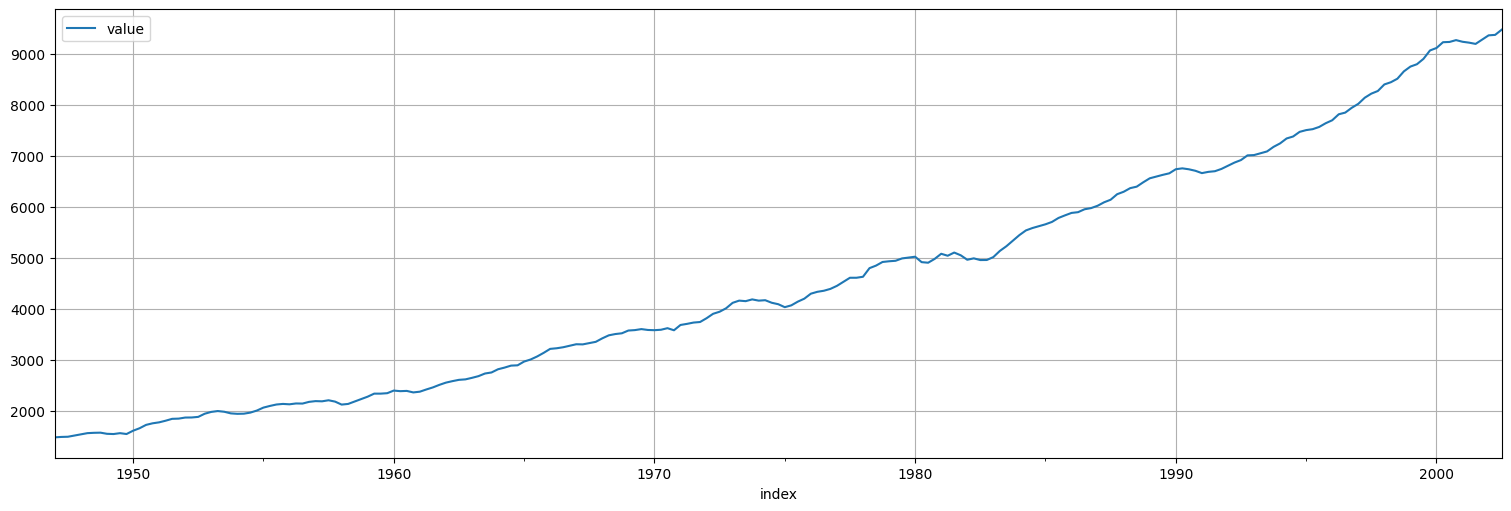
#Transformo por log
x=np.log(gnp)
x.plot();
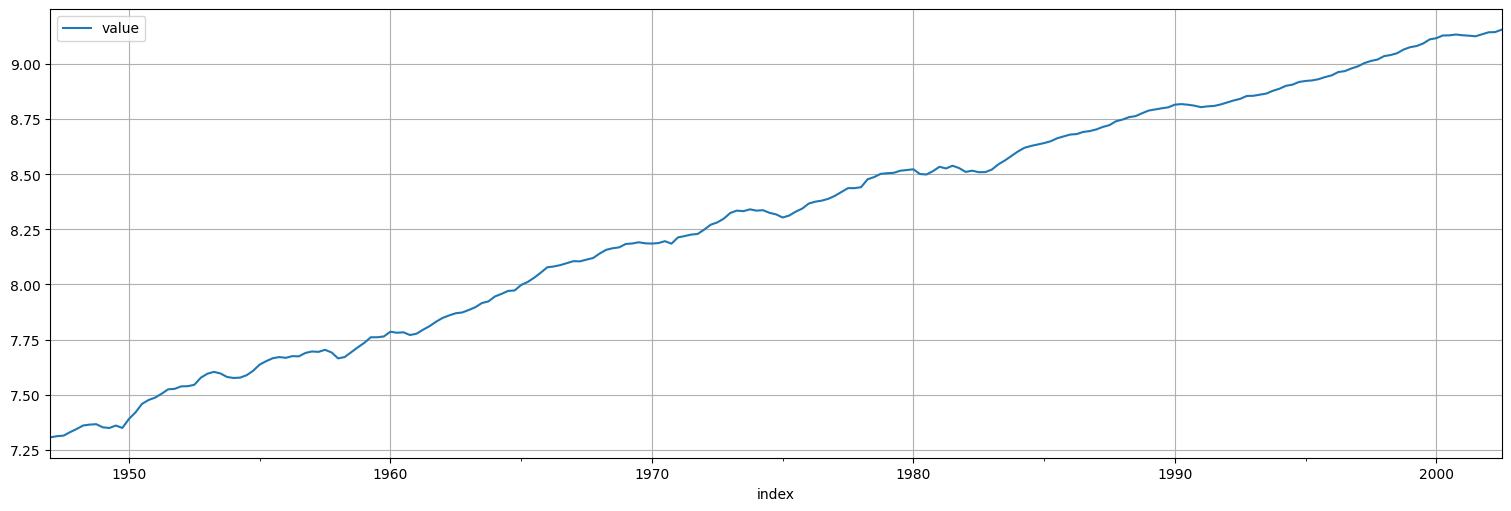
Hago la ACF solo par ver que no es estacionaria
plot_acf(x, bartlett_confint=False);
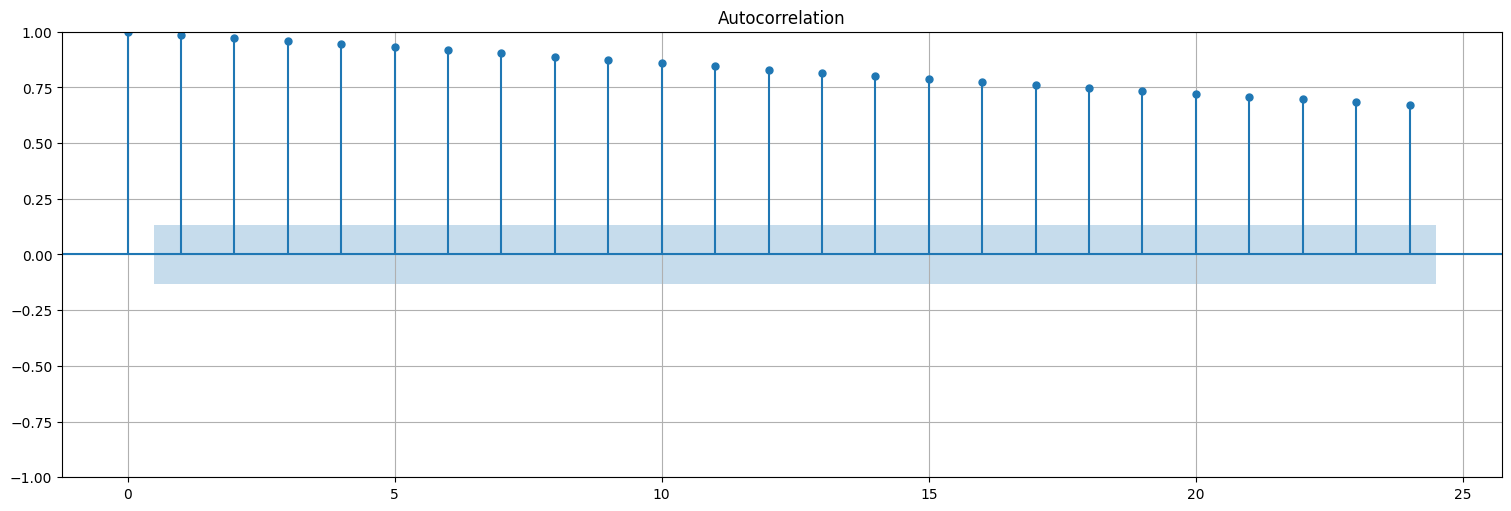
Diferencio la serie una vez y logro estacionariedad
y=x.diff().dropna()
y.plot()
plt.title(f"Serie de diferencias, μ = {np.mean(y)}");
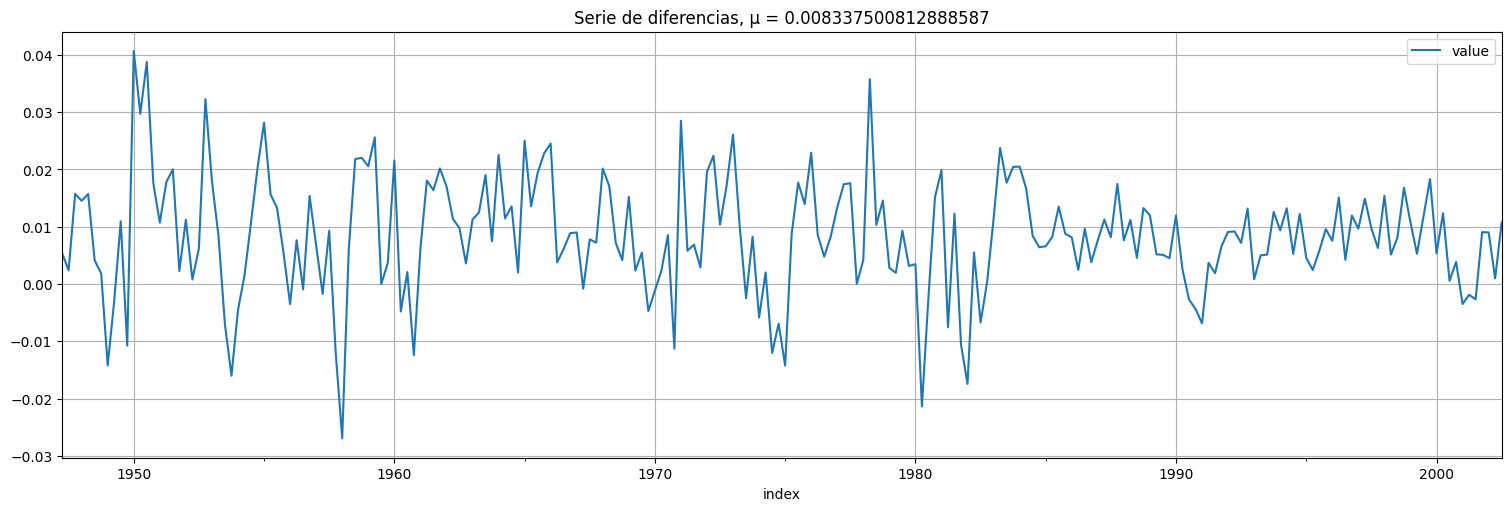
Analizamos ACF y PACF
plot_acf(y, bartlett_confint=False);
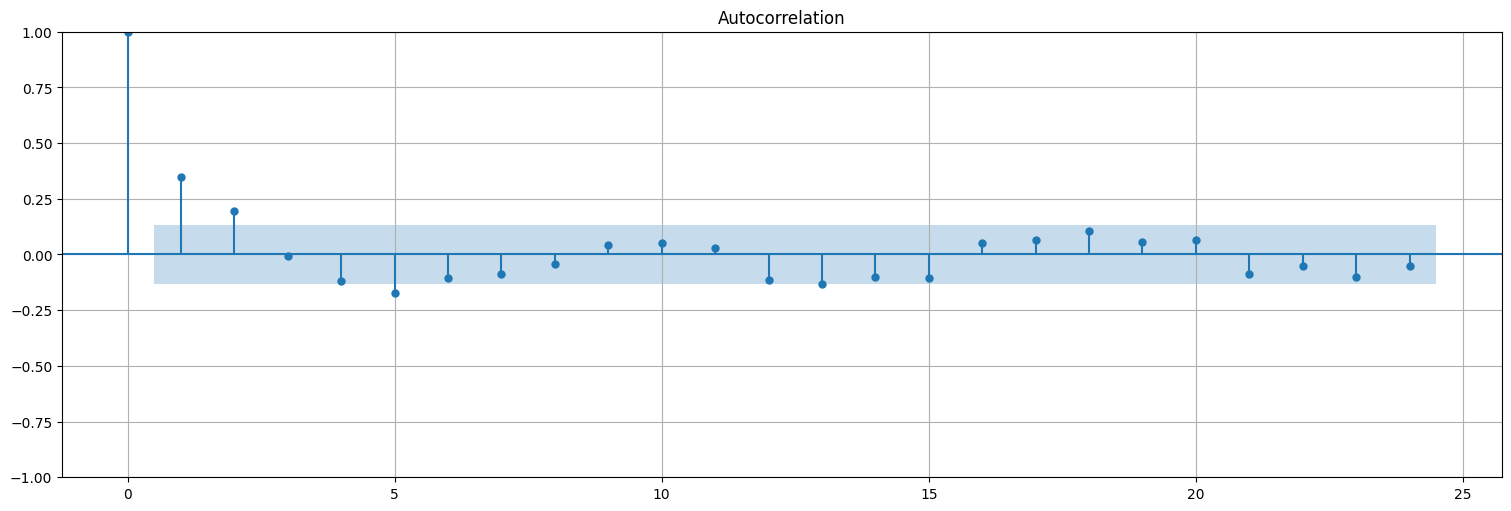
plot_pacf(y);
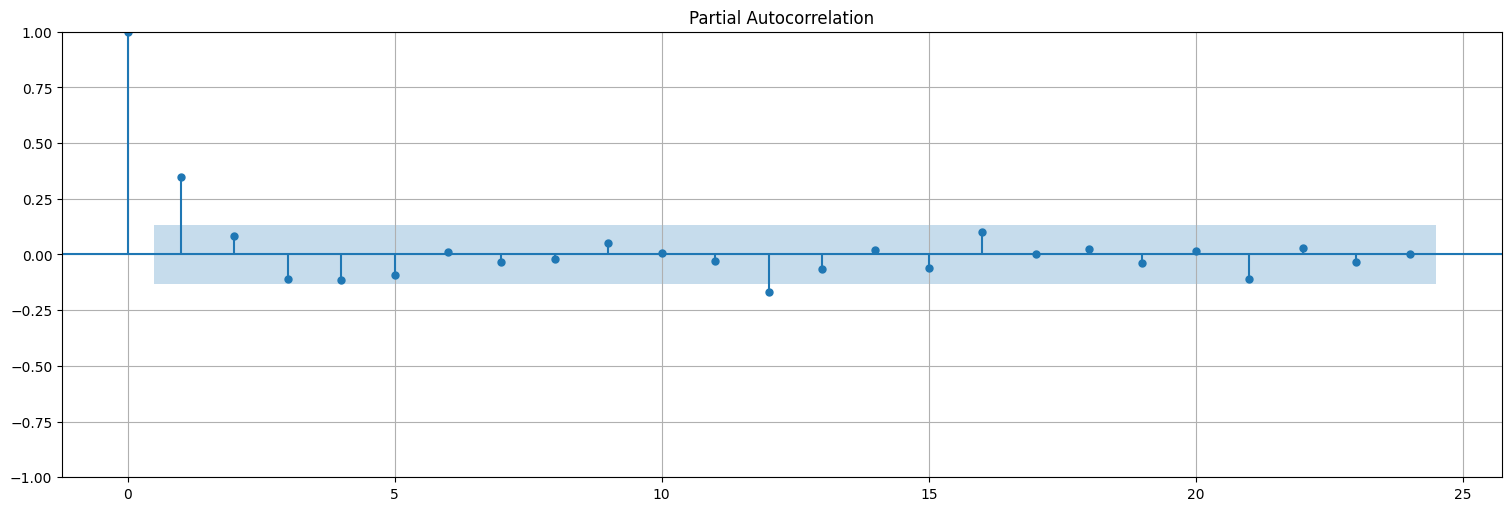
Mirando lo anterior podemos inclinarnos por varios modelos para \(x\):
ARIMA(1,1,0) ya que diferenciamos una vez y vemos que la PACF corta en 1.
ARIMA(0,1,2) ya que diferenciamos una vez y vemos que la ACF corta en 2.
Otras posibilidades a testear. Probemos y hagamos diagnóstico
Modelo 1: ARIMA(1,1,0)¶
fit = ARIMA(x,order=(1,1,0), trend="t").fit()
res = fit.resid[1:]; #acordarse de sacar el primero
print(f"RMSE: {np.std(res)}")
fit.summary()
RMSE: 0.009502645075030325
| Dep. Variable: | value | No. Observations: | 223 |
|---|---|---|---|
| Model: | ARIMA(1, 1, 0) | Log Likelihood | 718.610 |
| Date: | Mon, 19 May 2025 | AIC | -1431.220 |
| Time: | 16:25:36 | BIC | -1421.012 |
| Sample: | 03-31-1947 | HQIC | -1427.099 |
| - 09-30-2002 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| x1 | 0.0083 | 0.001 | 8.297 | 0.000 | 0.006 | 0.010 |
| ar.L1 | 0.3481 | 0.055 | 6.288 | 0.000 | 0.240 | 0.457 |
| sigma2 | 9.023e-05 | 6.47e-06 | 13.943 | 0.000 | 7.76e-05 | 0.000 |
| Ljung-Box (L1) (Q): | 0.18 | Jarque-Bera (JB): | 23.64 |
|---|---|---|---|
| Prob(Q): | 0.67 | Prob(JB): | 0.00 |
| Heteroskedasticity (H): | 0.19 | Skew: | 0.13 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 4.58 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
fig, axs = plt.subplots(1, 3)
res.plot(ax=axs[0])
axs[0].title.set_text(f"RMSE: {np.std(res)}")
plot_acf(res, ax=axs[1], bartlett_confint=False)
qqplot(res,line='s', ax=axs[2]);
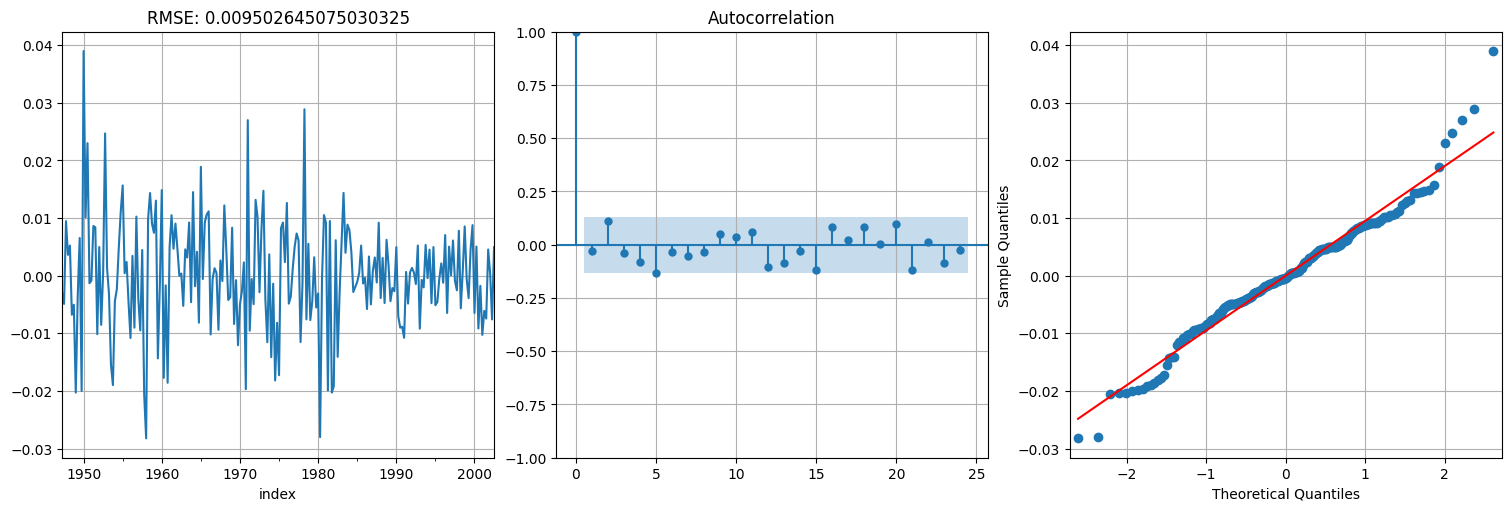
Modelo 2: ARIMA(0,1,2)¶
fit = ARIMA(x,order=(0,1,2), trend="t").fit()
res = fit.resid[1:]; #acordarse de sacar el primero
print(f"RMSE: {np.std(res)}")
fit.summary()
RMSE: 0.00944678036519239
| Dep. Variable: | value | No. Observations: | 223 |
|---|---|---|---|
| Model: | ARIMA(0, 1, 2) | Log Likelihood | 719.908 |
| Date: | Mon, 19 May 2025 | AIC | -1431.816 |
| Time: | 16:25:37 | BIC | -1418.206 |
| Sample: | 03-31-1947 | HQIC | -1426.321 |
| - 09-30-2002 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| x1 | 0.0083 | 0.001 | 8.389 | 0.000 | 0.006 | 0.010 |
| ma.L1 | 0.3067 | 0.054 | 5.649 | 0.000 | 0.200 | 0.413 |
| ma.L2 | 0.2249 | 0.056 | 4.028 | 0.000 | 0.115 | 0.334 |
| sigma2 | 8.92e-05 | 6.49e-06 | 13.752 | 0.000 | 7.65e-05 | 0.000 |
| Ljung-Box (L1) (Q): | 0.03 | Jarque-Bera (JB): | 21.82 |
|---|---|---|---|
| Prob(Q): | 0.86 | Prob(JB): | 0.00 |
| Heteroskedasticity (H): | 0.19 | Skew: | 0.13 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 4.51 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
fig, axs = plt.subplots(1, 3)
res.plot(ax=axs[0])
axs[0].title.set_text(f"RMSE: {np.std(res)}")
plot_acf(res, ax=axs[1], bartlett_confint=False)
qqplot(res,line='s', ax=axs[2]);
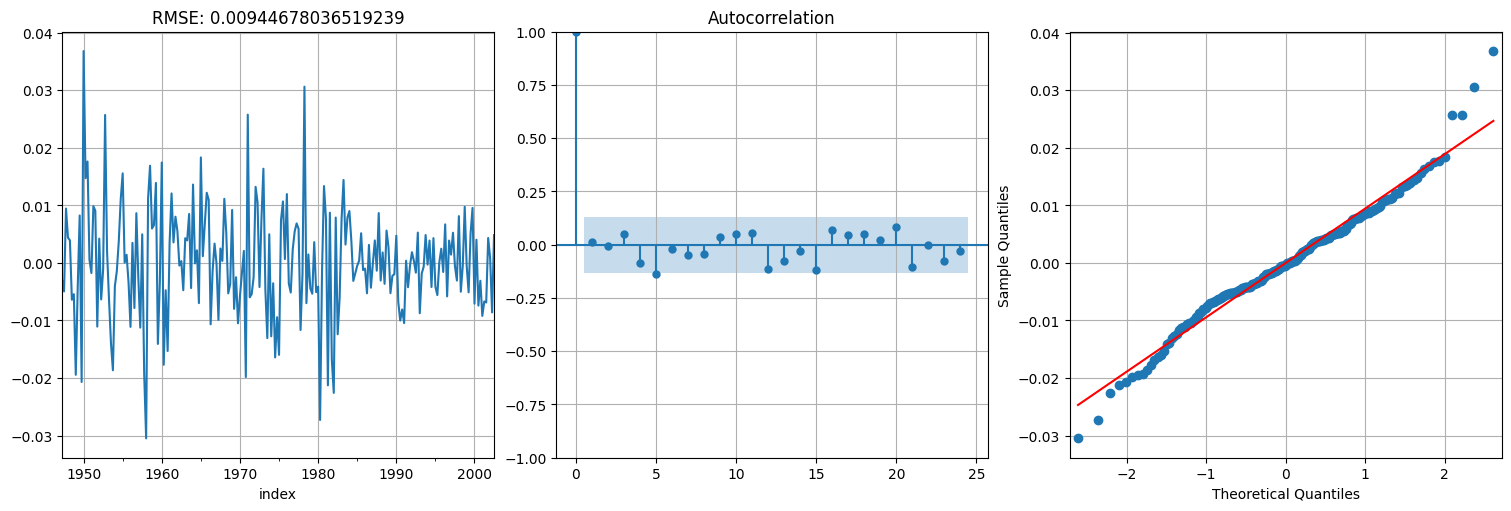
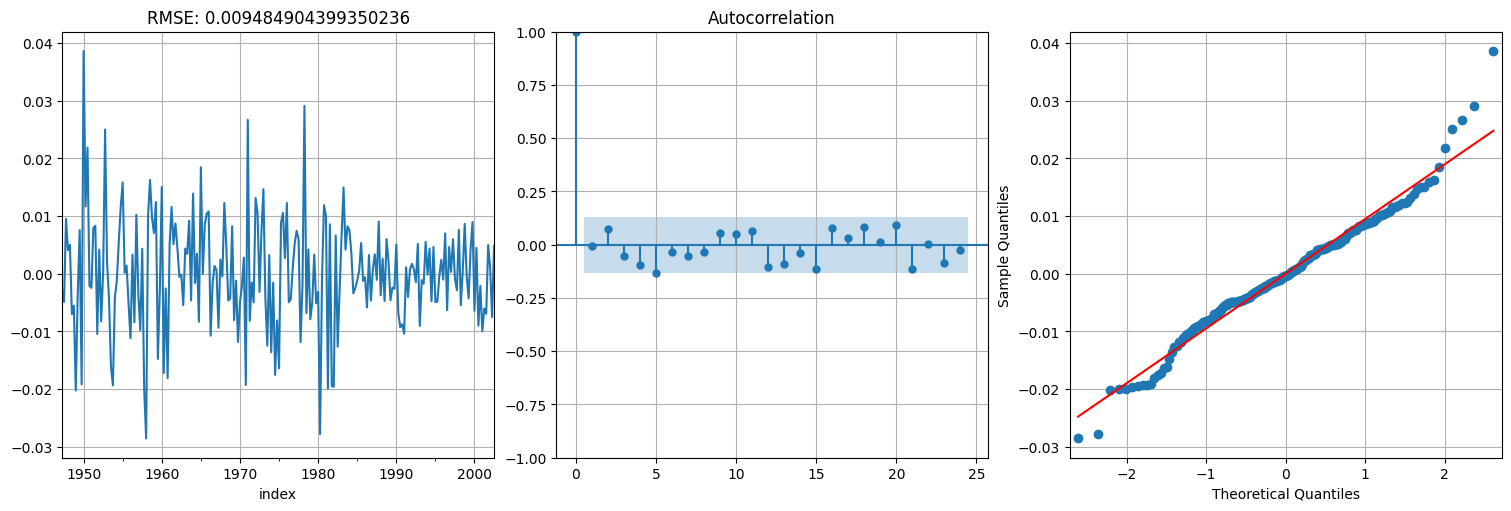
Como vemos, dan bastante parecidos, con leve ventaja para el \(MA(2)\). Probemos combinar ambas en un ARIMA(1,1,1), es decir, media móvil de orden 1 y autorregresivo de orden 1 luego de diferenciar.
fit = ARIMA(x,order=(1,1,1), trend="t").fit()
res = fit.resid[1:]; #acordarse de sacar el primero
print(f"RMSE: {np.std(res)}")
fit.summary()
RMSE: 0.009484904399350236
| Dep. Variable: | value | No. Observations: | 223 |
|---|---|---|---|
| Model: | ARIMA(1, 1, 1) | Log Likelihood | 719.022 |
| Date: | Mon, 19 May 2025 | AIC | -1430.044 |
| Time: | 16:25:38 | BIC | -1416.433 |
| Sample: | 03-31-1947 | HQIC | -1424.549 |
| - 09-30-2002 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| x1 | 0.0083 | 0.001 | 7.651 | 0.000 | 0.006 | 0.010 |
| ar.L1 | 0.4854 | 0.162 | 2.992 | 0.003 | 0.167 | 0.803 |
| ma.L1 | -0.1552 | 0.178 | -0.871 | 0.384 | -0.505 | 0.194 |
| sigma2 | 8.994e-05 | 6.55e-06 | 13.728 | 0.000 | 7.71e-05 | 0.000 |
| Ljung-Box (L1) (Q): | 0.00 | Jarque-Bera (JB): | 22.25 |
|---|---|---|---|
| Prob(Q): | 0.95 | Prob(JB): | 0.00 |
| Heteroskedasticity (H): | 0.19 | Skew: | 0.15 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 4.52 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
fig, axs = plt.subplots(1, 3)
res.plot(ax=axs[0])
axs[0].title.set_text(f"RMSE: {np.std(res)}")
plot_acf(res, ax=axs[1], bartlett_confint=False)
qqplot(res,line='s', ax=axs[2]);
Validación de residuos: estadístico de Ljung-Box-Pierce¶
La serie anterior de residuos parece haber quedado “blanca”. Sin embargo, es bueno disponer de un test que permita evaluar si la ACF en su conjunto es razonablemente blanca en lugar de mirar lag a lag. Para ello se usa el estadístico de Ljung-Box-Pierce.
donde \(H\) es una ventana. La idea de este estadístico es acumular varias correlaciones en la ventana \(H\) para ver si en su conjunto son todas despreciables (en lugar de una a una).
El estadístico \(Q\) es asintóticamente \(\chi^2_{H-p-q}\) por lo que si el valor de \(Q\) es grande (más que el cuantil \(\alpha\) de la \(\chi^2\)) rechazamos la hipótesis de independencia.
En general lo que se hace es mirar los \(p\)-valores, es decir cuánta probabilidad queda a la derecha de \(Q\). Si es pequeño (ej: \(p<0.05\)) se rechaza la hipótesis.
from statsmodels.stats.api import acorr_ljungbox
acorr_ljungbox(res,10)
| lb_stat | lb_pvalue | |
|---|---|---|
| 1 | 0.003281 | 0.954324 |
| 2 | 1.197290 | 0.549556 |
| 3 | 1.811029 | 0.612538 |
| 4 | 3.849914 | 0.426699 |
| 5 | 8.023301 | 0.154956 |
| 6 | 8.289443 | 0.217656 |
| 7 | 8.906550 | 0.259435 |
| 8 | 9.149590 | 0.329834 |
| 9 | 9.838461 | 0.363720 |
| 10 | 10.428248 | 0.403758 |
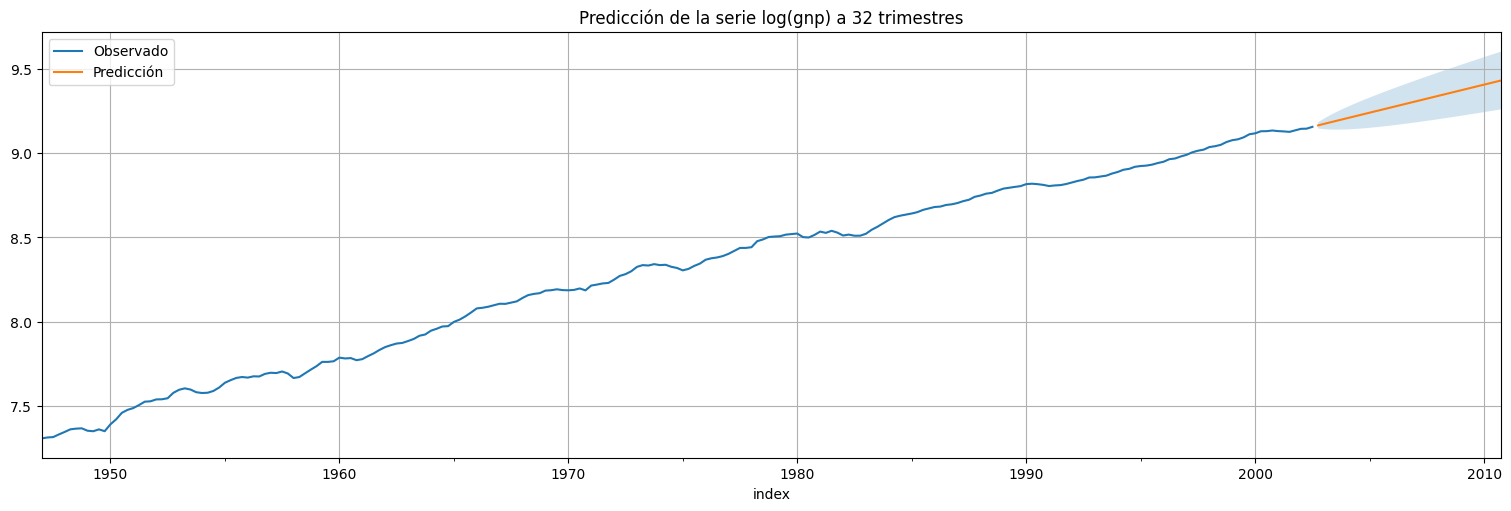
Predicción:¶
Como último paso pasamos a la predicción a \(2\) años (8 trimestres):
#Usamos el modelo ajustado para predecir a futuro
h = 32 #horizonte de predicción
predicciones = fit.get_prediction(start=gnp.size,end=gnp.size+h)
xhat = predicciones.predicted_mean
confint = predicciones.conf_int(alpha=0.05) #alpha es la confianza del intervalo
x.plot()
xhat.plot()
plt.legend(["Observado","Predicción"])
plt.fill_between(xhat.index,confint["lower value"], confint["upper value"], alpha=0.2);
plt.title(f"Predicción de la serie log(gnp) a {h} trimestres");
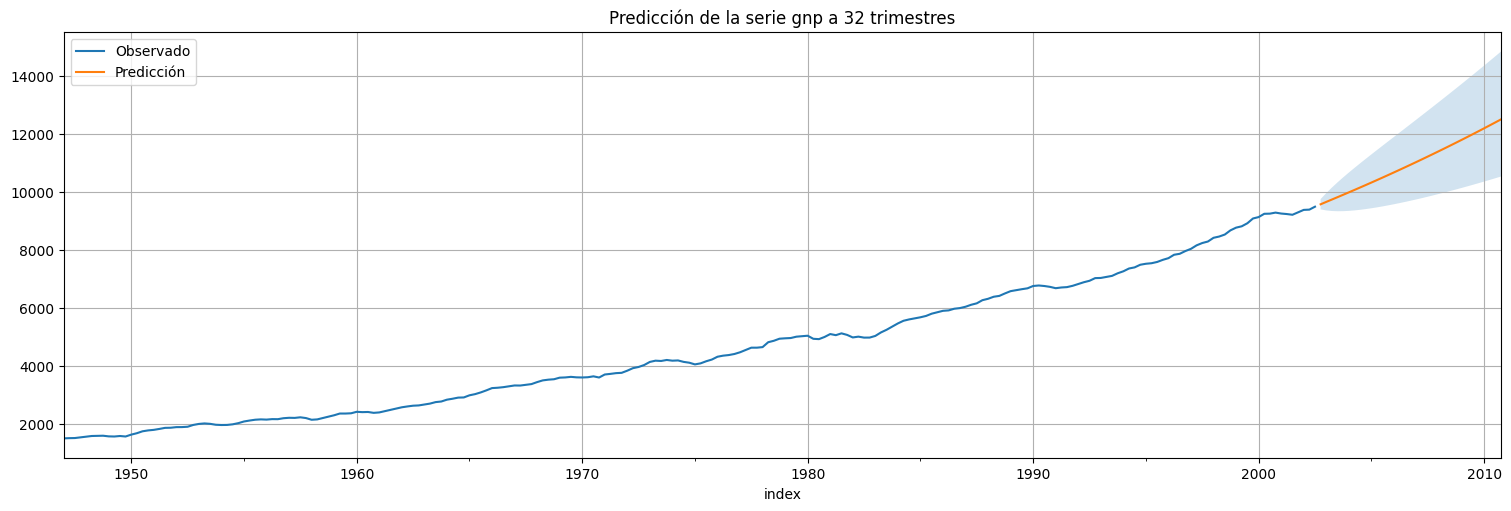
Ahora podemos volver a la variable original, deshaciendo la transformación \(x\to \log(x)\) mediante \(y\to \exp(y)\):
gnp.plot()
estimated_gnp = np.exp(xhat)
confint_exp = np.exp(confint)
estimated_gnp.plot()
plt.legend(["Observado","Predicción"])
plt.fill_between(xhat.index,confint_exp["lower value"], confint_exp["upper value"], alpha=0.2);
plt.title(f"Predicción de la serie gnp a {h} trimestres");
Modelos ARIMA estacionales (SARIMA)¶
Una variante muy utilizada de los modelos ARMA (ARIMA) es aquella que agrega dependencia estacional. Es decir, existe algún período conocido \(s\) de la serie llamado componente estacional que se conoce tiene influencia en el valor actual. Por ejemplo \(s=12\) en series anuales muestreadas mensualmente.
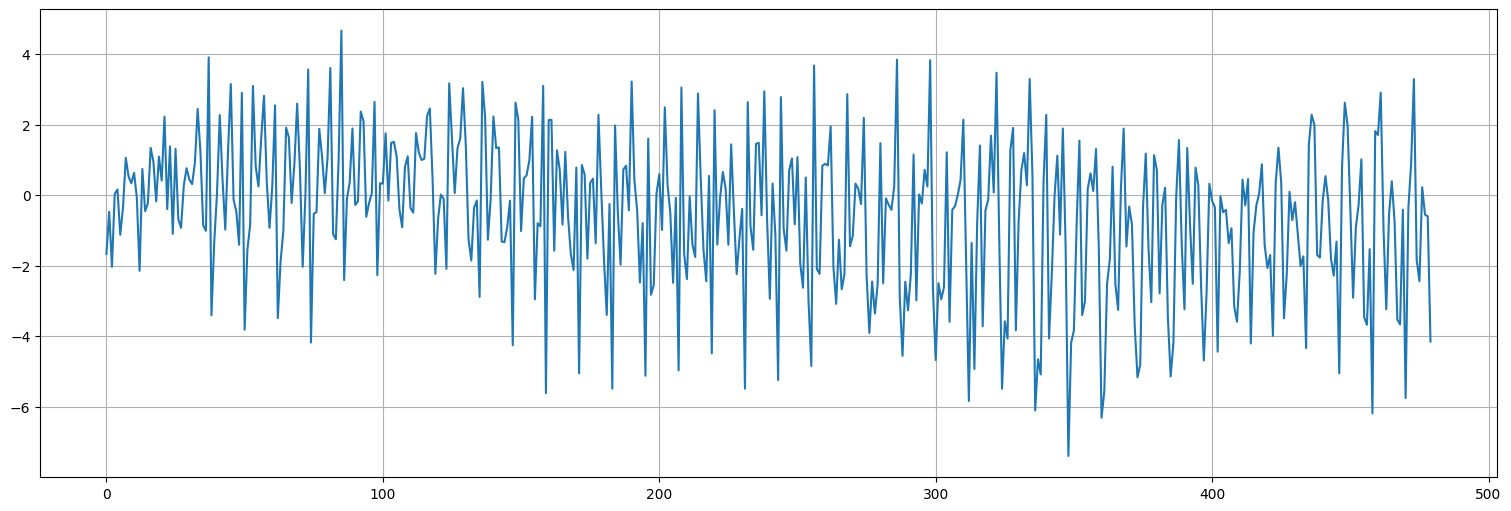
Ejemplo (AR estacional puro)¶
Supongamos que la serie sigue la siguiente ecuación:
con \(\Phi\) un coeficiente y \(w_t\) ruido blanco Gaussiano de varianza \(\sigma^2_w\)
El proceso anterior lo podemos pensar simplemente como un proceso \(AR(12)\), pero cuyos coeficientes intermedios son todos \(0\).
Phi=0.9
coefs = np.concatenate(([1],np.zeros(11),[-Phi]))
print(f"Coeficientes autorregresivos = {coefs}")
x = arma_generate_sample(coefs,[1],480)
x = pd.Series(x)
x.plot();
Coeficientes autorregresivos = [ 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. -0.9]
Miremos la ACF y PACF de esta serie:
plot_acf(x, lags=36,bartlett_confint=False);
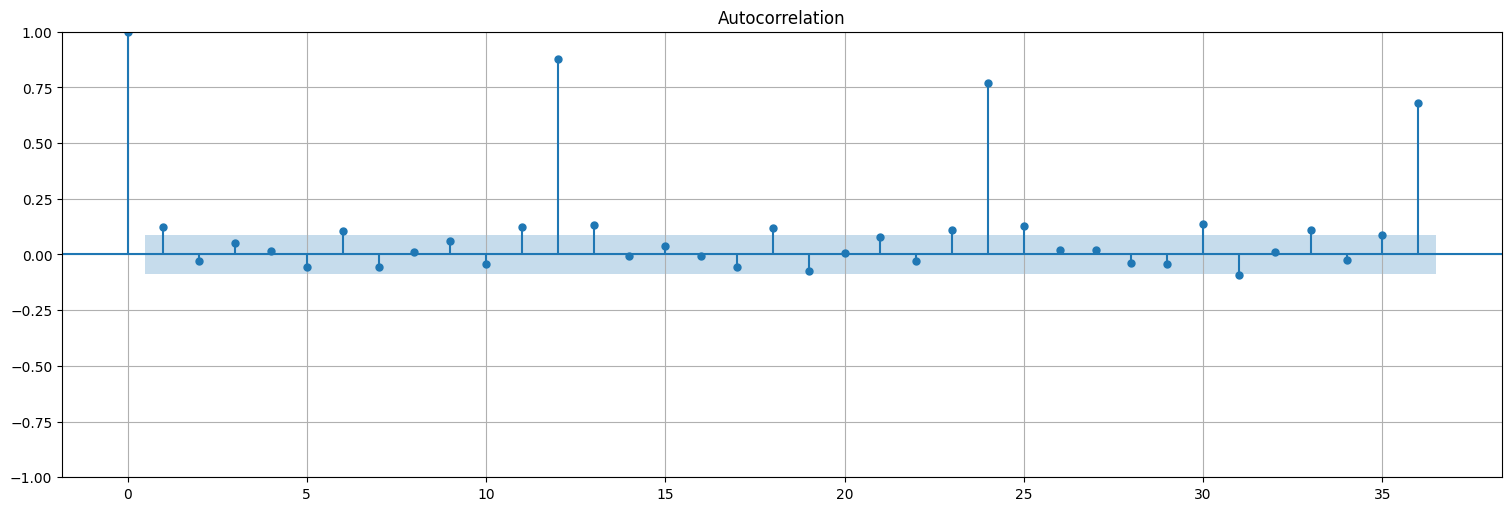
plot_pacf(x);
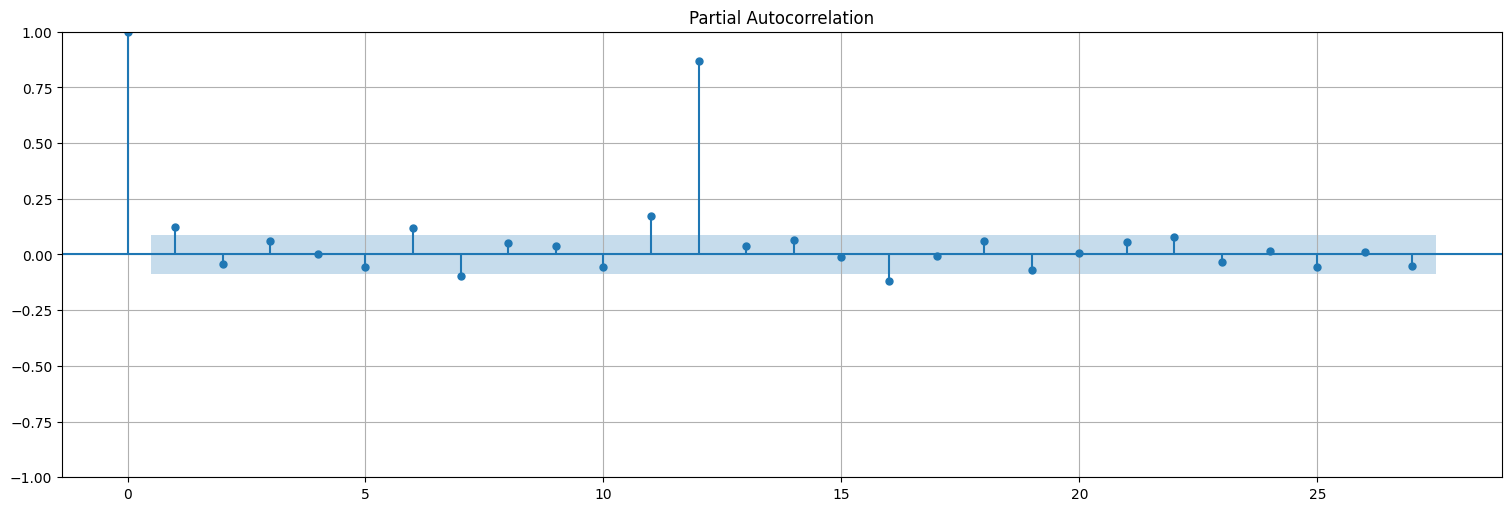
Y en principio se puede realizar el ajuste de la misma manera que antes:
fit = ARIMA(x,order=(12,0,0), trend="n").fit()
fit.summary()
| Dep. Variable: | y | No. Observations: | 480 |
|---|---|---|---|
| Model: | ARIMA(12, 0, 0) | Log Likelihood | -671.830 |
| Date: | Mon, 19 May 2025 | AIC | 1369.660 |
| Time: | 16:25:53 | BIC | 1423.919 |
| Sample: | 0 | HQIC | 1390.988 |
| - 480 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| ar.L1 | 0.0207 | 0.020 | 1.034 | 0.301 | -0.019 | 0.060 |
| ar.L2 | 0.0091 | 0.023 | 0.393 | 0.694 | -0.036 | 0.054 |
| ar.L3 | 0.0010 | 0.022 | 0.046 | 0.964 | -0.042 | 0.044 |
| ar.L4 | 0.0138 | 0.023 | 0.587 | 0.557 | -0.032 | 0.060 |
| ar.L5 | -0.0115 | 0.023 | -0.505 | 0.614 | -0.056 | 0.033 |
| ar.L6 | 0.0140 | 0.024 | 0.590 | 0.555 | -0.033 | 0.061 |
| ar.L7 | -0.0031 | 0.022 | -0.143 | 0.886 | -0.046 | 0.040 |
| ar.L8 | 0.0025 | 0.021 | 0.120 | 0.904 | -0.038 | 0.043 |
| ar.L9 | 0.0145 | 0.022 | 0.672 | 0.502 | -0.028 | 0.057 |
| ar.L10 | -0.0187 | 0.021 | -0.910 | 0.363 | -0.059 | 0.022 |
| ar.L11 | 0.0251 | 0.020 | 1.253 | 0.210 | -0.014 | 0.064 |
| ar.L12 | 0.8835 | 0.020 | 43.494 | 0.000 | 0.844 | 0.923 |
| sigma2 | 0.9248 | 0.065 | 14.189 | 0.000 | 0.797 | 1.053 |
| Ljung-Box (L1) (Q): | 1.21 | Jarque-Bera (JB): | 0.90 |
|---|---|---|---|
| Prob(Q): | 0.27 | Prob(JB): | 0.64 |
| Heteroskedasticity (H): | 1.06 | Skew: | 0.08 |
| Prob(H) (two-sided): | 0.73 | Kurtosis: | 2.86 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Sin embargo, si uno sabe que los coeficientes son \(0\), es mejor obviarlos para lograr un mejor ajuste del coeficiente no nulo. Esto se logra proponiendo un modelo \(ARMA(p,q)\times(P,Q)_s\). Aquí \((p,q)\) son las componentes ARMA como antes, y \((P,Q)_s\) indican dependencia a estaciones pasadas (dadas por el período \(s\)).
En la función ARIMA de statsmodels esto se hace pasándole el parámetro seasonal_order=(P,D,Q,s) donde \(P\) es la parte autorregresiva estacional, \(D\) la diferenciación estacional (no va en este caso), \(Q\) la parte media móvil estacional, y \(s\) el período, en este caso \(12\).
fit = ARIMA(x,order=(0,0,0), seasonal_order=(1, 0, 0, 12),trend="n").fit()
fit.summary()
| Dep. Variable: | y | No. Observations: | 480 |
|---|---|---|---|
| Model: | ARIMA(1, 0, 0, 12) | Log Likelihood | -674.201 |
| Date: | Mon, 19 May 2025 | AIC | 1352.402 |
| Time: | 16:25:55 | BIC | 1360.750 |
| Sample: | 0 | HQIC | 1355.683 |
| - 480 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| ar.S.L12 | 0.8966 | 0.019 | 46.546 | 0.000 | 0.859 | 0.934 |
| sigma2 | 0.9329 | 0.063 | 14.899 | 0.000 | 0.810 | 1.056 |
| Ljung-Box (L1) (Q): | 0.47 | Jarque-Bera (JB): | 0.86 |
|---|---|---|---|
| Prob(Q): | 0.49 | Prob(JB): | 0.65 |
| Heteroskedasticity (H): | 1.07 | Skew: | 0.09 |
| Prob(H) (two-sided): | 0.68 | Kurtosis: | 2.89 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Ejemplo: combinación de AR estacional y MA local.¶
Consideremos el proceso:
En este caso tenemos un proceso \(ARMA(0,1)\times(1,0)_{12}\).
Consideremos la siguiente serie de nacimientos en EEUU durante el “baby boom”:
birth = astsa.birth
birth.plot();
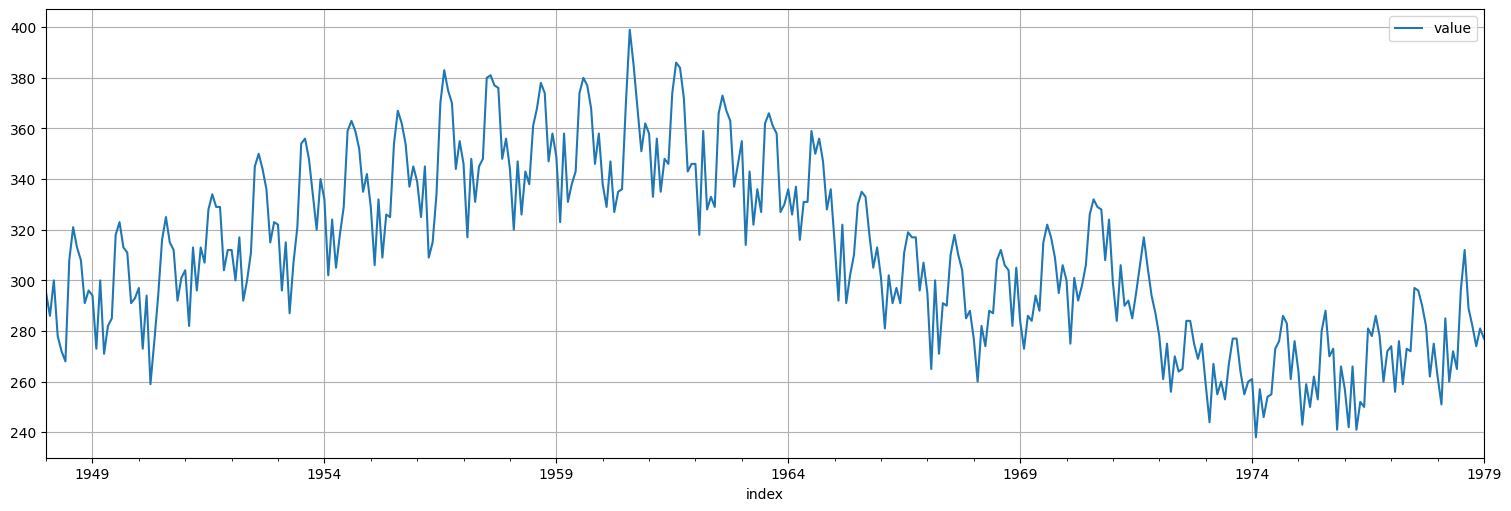
Diferenciemos una vez para lograr estacionariedad:
x = birth.diff().dropna()
x.plot();
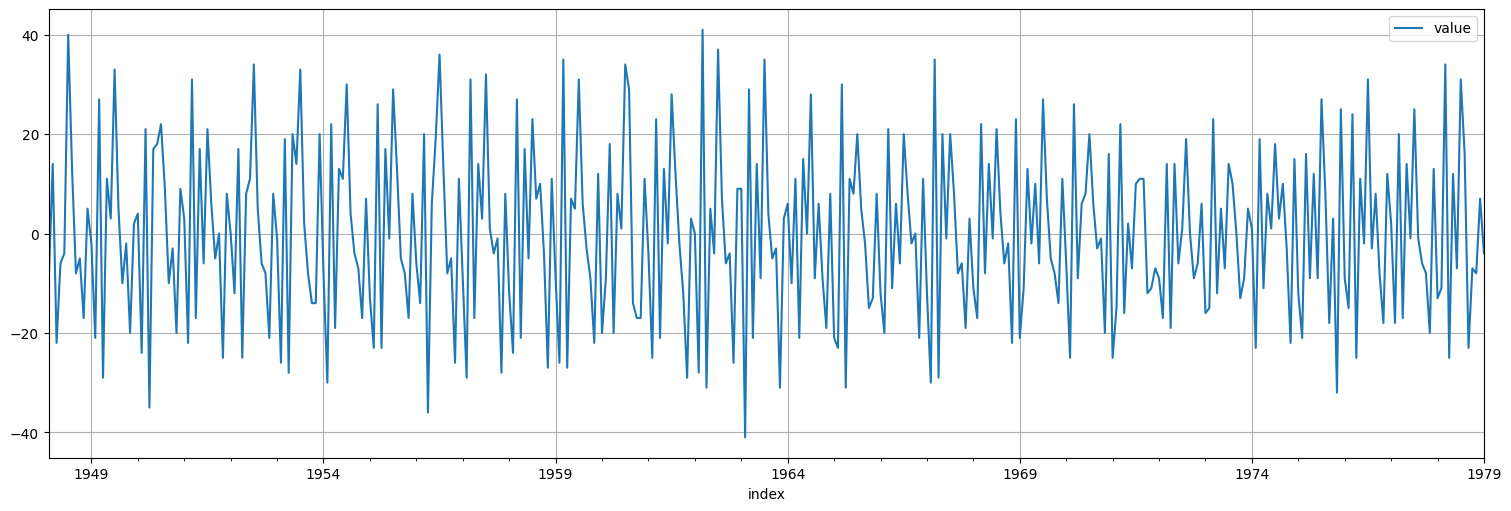
plot_acf(x, bartlett_confint=False);
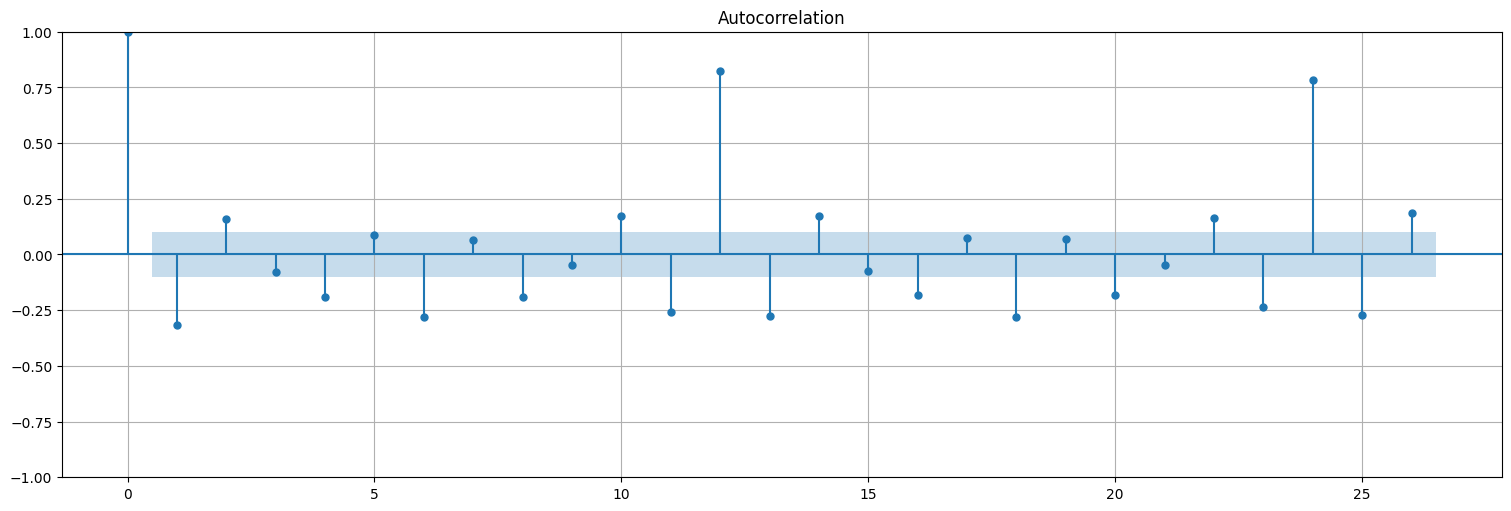
plot_pacf(x);
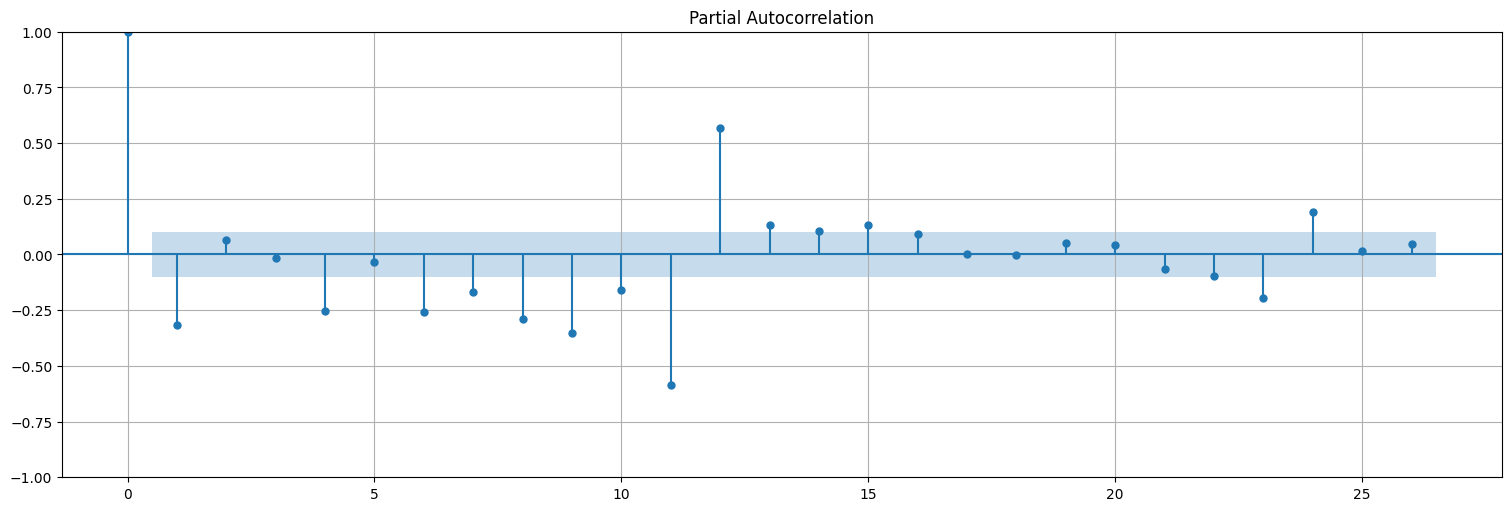
Ajustamos ahora el modelo anterior \(x_t = \Phi x_{t-12} + w_t + \theta w_{t-1}\), es decir, \(ARMA(0,1)\times(1,0)_{12}\).
fit = ARIMA(x,order=(0,0,1), seasonal_order=(1, 0, 0, 12),trend="n").fit()
fit.summary()
| Dep. Variable: | value | No. Observations: | 372 |
|---|---|---|---|
| Model: | ARIMA(0, 0, 1)x(1, 0, [], 12) | Log Likelihood | -1318.522 |
| Date: | Mon, 19 May 2025 | AIC | 2643.044 |
| Time: | 16:26:06 | BIC | 2654.801 |
| Sample: | 02-29-1948 | HQIC | 2647.713 |
| - 01-31-1979 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| ma.L1 | -0.5035 | 0.043 | -11.823 | 0.000 | -0.587 | -0.420 |
| ar.S.L12 | 0.8697 | 0.023 | 37.533 | 0.000 | 0.824 | 0.915 |
| sigma2 | 66.9941 | 4.620 | 14.500 | 0.000 | 57.939 | 76.049 |
| Ljung-Box (L1) (Q): | 2.76 | Jarque-Bera (JB): | 1.90 |
|---|---|---|---|
| Prob(Q): | 0.10 | Prob(JB): | 0.39 |
| Heteroskedasticity (H): | 0.99 | Skew: | 0.11 |
| Prob(H) (two-sided): | 0.94 | Kurtosis: | 3.27 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Agreguemos una predicción a futuro:
#Usamos el modelo ajustado para predecir a futuro
h = 24 #horizonte de predicción
predicciones = fit.get_prediction(start=birth.size,end=birth.size+h)
xhat = predicciones.predicted_mean
confint = predicciones.conf_int(alpha=0.05) #alpha es la confianza del intervalo
x.plot()
xhat.plot()
plt.legend(["Observado","Predicción"])
plt.fill_between(xhat.index,confint["lower value"], confint["upper value"], alpha=0.2);
plt.title(f"Predicción de la serie diff(birth) a {h} meses");
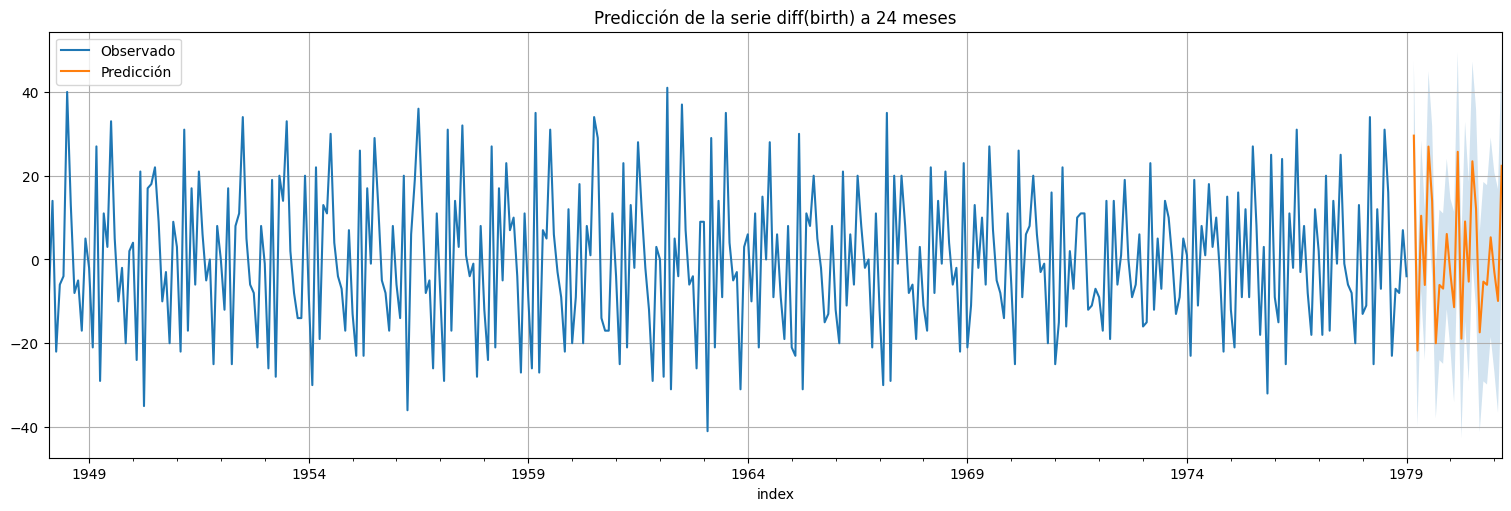
Modelo SARIMA general¶
En el ejemplo anterior, tuvimos que diferenciar la serie birth para lograr algo estacionario. Esto nos lleva al modelo SARIMA general, en el cual los parámetros son:
\((p,d,q)\), las componentes locales del modelo sarima. \(d\) es la cantidad de veces que hay que diferenciar con la muestra anterior.
\((P,D,Q)\), las componentes estacionales del modelo sarima. \(D\) es la cantidad de veces que hay que diferenciar con la estación anterior.
\(s\) es la frecuencia de las estaciones.
Para el caso anterior, podemos directamente ajustar un modelo \(SARIMA(0,1,1)\times (1,0,0)_{12}\) pasándole el problema de diferenciar al ajuste.
birth
fit = ARIMA(birth,order=(0,1,1), seasonal_order=(1, 0, 0, 12),trend="n").fit()
fit.summary()
| Dep. Variable: | value | No. Observations: | 373 |
|---|---|---|---|
| Model: | ARIMA(0, 1, 1)x(1, 0, [], 12) | Log Likelihood | -1318.523 |
| Date: | Mon, 19 May 2025 | AIC | 2643.046 |
| Time: | 16:26:11 | BIC | 2654.803 |
| Sample: | 01-31-1948 | HQIC | 2647.715 |
| - 01-31-1979 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| ma.L1 | -0.5035 | 0.043 | -11.823 | 0.000 | -0.587 | -0.420 |
| ar.S.L12 | 0.8697 | 0.023 | 37.533 | 0.000 | 0.824 | 0.915 |
| sigma2 | 66.9942 | 4.620 | 14.500 | 0.000 | 57.939 | 76.050 |
| Ljung-Box (L1) (Q): | 2.76 | Jarque-Bera (JB): | 1.90 |
|---|---|---|---|
| Prob(Q): | 0.10 | Prob(JB): | 0.39 |
| Heteroskedasticity (H): | 0.99 | Skew: | 0.11 |
| Prob(H) (two-sided): | 0.94 | Kurtosis: | 3.27 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
#Usamos el modelo ajustado para predecir a futuro
h = 24 #horizonte de predicción
predicciones = fit.get_prediction(start=birth.size,end=birth.size+h)
xhat = predicciones.predicted_mean
confint = predicciones.conf_int(alpha=0.05) #alpha es la confianza del intervalo
birth.plot()
xhat.plot()
plt.legend(["Observado","Predicción"])
plt.fill_between(xhat.index,confint["lower value"], confint["upper value"], alpha=0.2);
plt.title(f"Predicción de la serie diff(birth) a {h} meses");
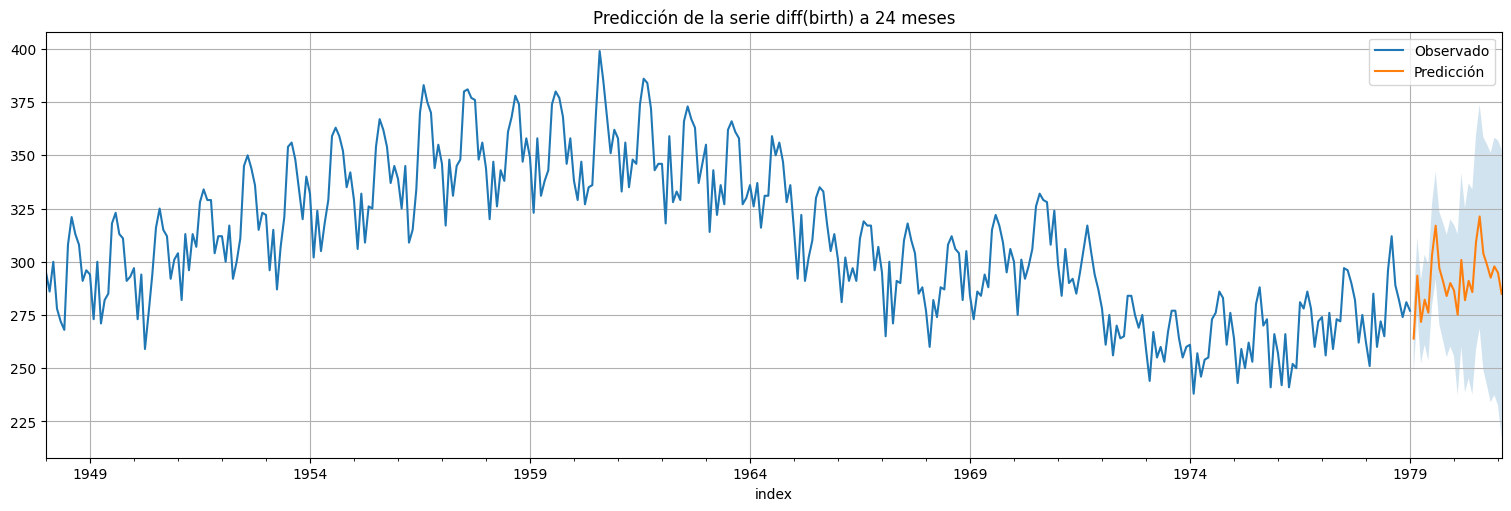
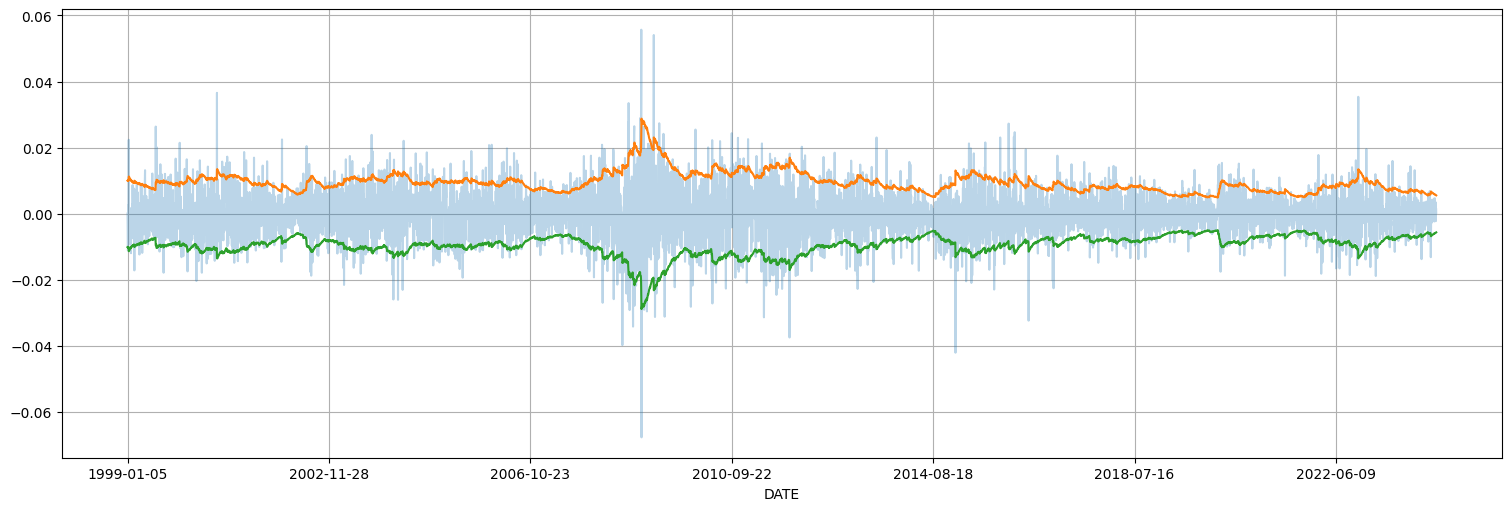
Modelos GARCH¶
Esta familia de modelos permiten modelar series cuya varianza no es estacionaria, como la que vimos anteriormente para el EUR vs USD
y = eur.diff().dropna()
y.plot();
plt.title(f"Media de las diferencias {np.mean(y)} +- {2*np.std(y)/np.sqrt(y.size)}");
Idea:¶
Modelar la varianza de la serie como un proceso autorregresivo. Si la serie está centrada, esto es equivalente a ajustar un modelo ARMA a los valores de \(x_t^2\). Este modelo se llama \(GARCH\): Generalized autorregressive conditionally heteroskedastic.
y2 = y**2
y2.plot();
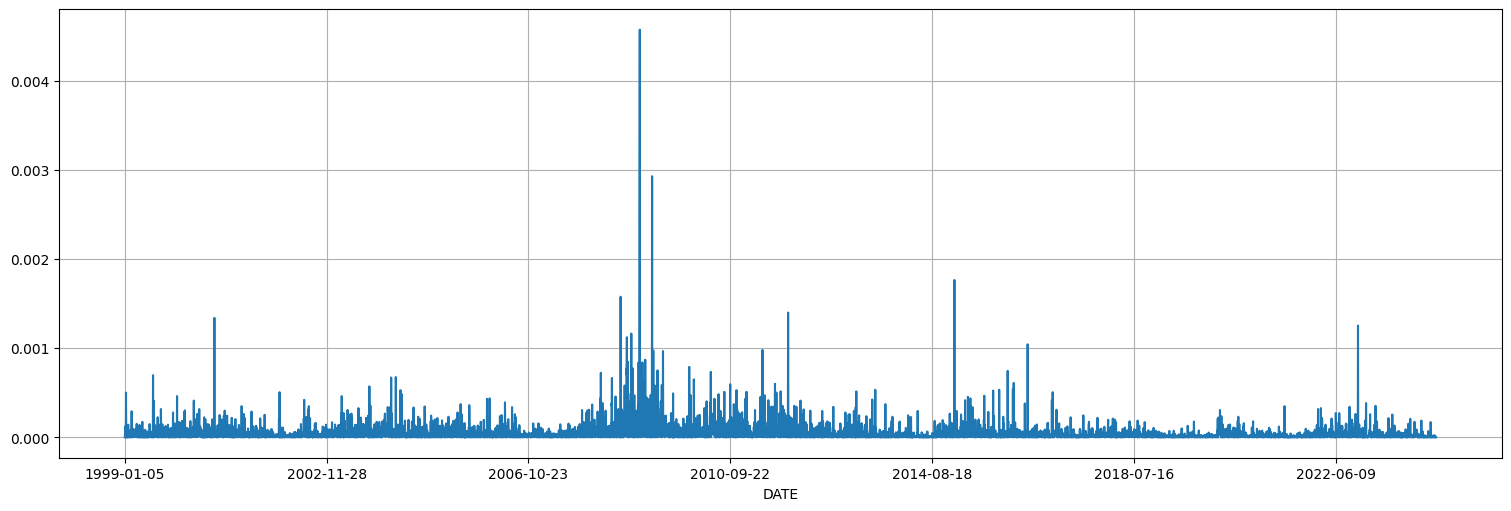
plot_acf(y2,bartlett_confint=False);
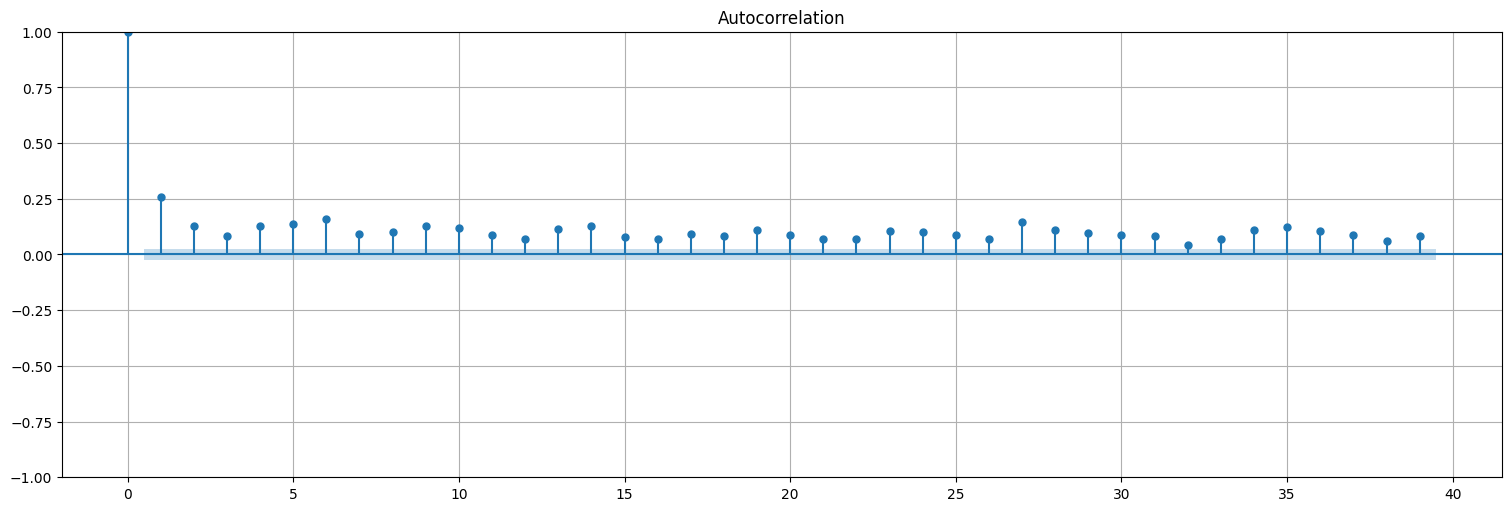
plot_pacf(y2);
La biblioteca statsmodels no incluye modelos tipo GARCH por lo que requerimos la biblioteca arch
from arch import arch_model
fit = arch_model(y, mean='Zero', vol='GARCH', p=1,q=1, rescale=True).fit();
fit.summary()
Iteration: 1, Func. Count: 5, Neg. LLF: 3542121476.1780243
Iteration: 2, Func. Count: 12, Neg. LLF: 6432.502659518372
Iteration: 3, Func. Count: 16, Neg. LLF: 13054.967420877505
Iteration: 4, Func. Count: 21, Neg. LLF: 8158.432872015319
Iteration: 5, Func. Count: 28, Neg. LLF: 9559.09420278957
Iteration: 6, Func. Count: 33, Neg. LLF: 8652.224376988284
Iteration: 7, Func. Count: 39, Neg. LLF: 7699.221113600659
Iteration: 8, Func. Count: 45, Neg. LLF: 6407.88196659977
Iteration: 9, Func. Count: 49, Neg. LLF: 6407.647697238508
Iteration: 10, Func. Count: 53, Neg. LLF: 6407.620967274368
Iteration: 11, Func. Count: 57, Neg. LLF: 6407.619060270876
Iteration: 12, Func. Count: 61, Neg. LLF: 6407.6189735249945
Iteration: 13, Func. Count: 64, Neg. LLF: 6407.6189735213
Optimization terminated successfully (Exit mode 0)
Current function value: 6407.6189735249945
Iterations: 13
Function evaluations: 64
Gradient evaluations: 13
| Dep. Variable: | None | R-squared: | 0.000 |
|---|---|---|---|
| Mean Model: | Zero Mean | Adj. R-squared: | 0.000 |
| Vol Model: | GARCH | Log-Likelihood: | -6407.62 |
| Distribution: | Normal | AIC: | 12821.2 |
| Method: | Maximum Likelihood | BIC: | 12841.6 |
| No. Observations: | 6499 | ||
| Date: | Mon, May 19 2025 | Df Residuals: | 6499 |
| Time: | 16:26:23 | Df Model: | 0 |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| omega | 1.2267e-03 | 5.081e-04 | 2.414 | 1.577e-02 | [2.309e-04,2.223e-03] |
| alpha[1] | 0.0282 | 3.649e-03 | 7.720 | 1.168e-14 | [2.102e-02,3.532e-02] |
| beta[1] | 0.9694 | 3.914e-03 | 247.714 | 0.000 | [ 0.962, 0.977] |
Covariance estimator: robust
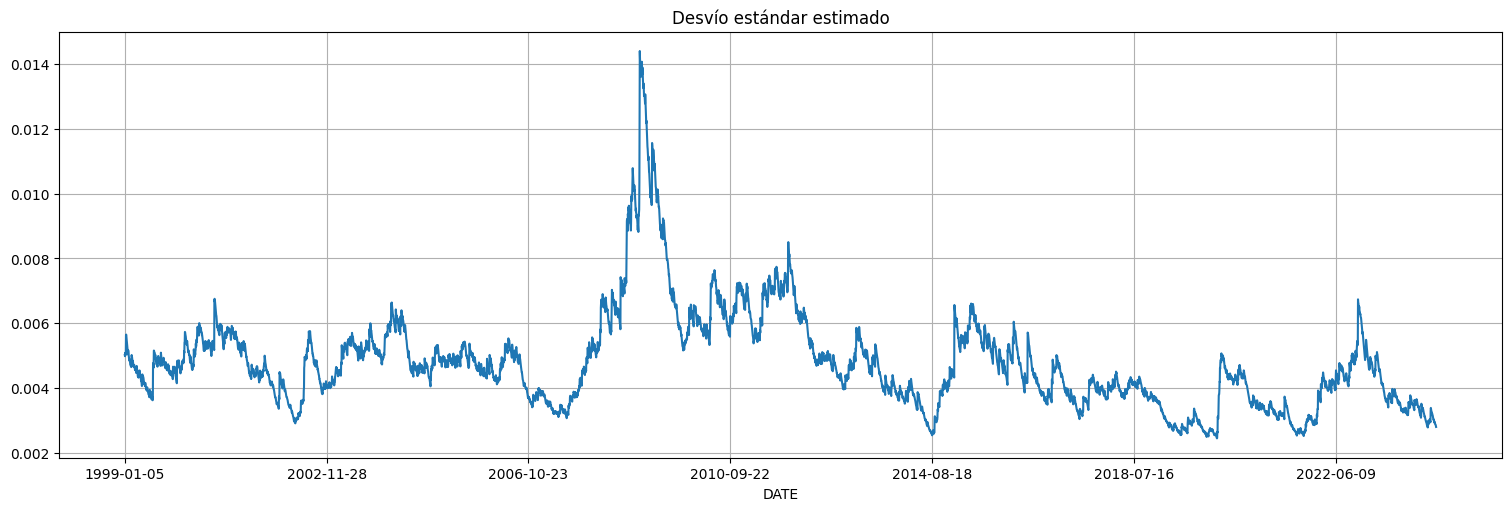
#Obtenemos los valores de varianza estimada por el modelo ajustado
#Horizon=1 es que predice el valor siguiente, start=0 es que arranca al comienzo de la serie)
predicciones = fit.forecast(horizon=1,start=0).variance
predicciones = pd.Series(predicciones["h.1"])
desvio = np.sqrt(predicciones)*np.std(y)
desvio.plot();
plt.title("Desvío estándar estimado");
y.plot(alpha=0.3)
(2*desvio).plot()
(-2*desvio).plot();
Ejercicios:¶
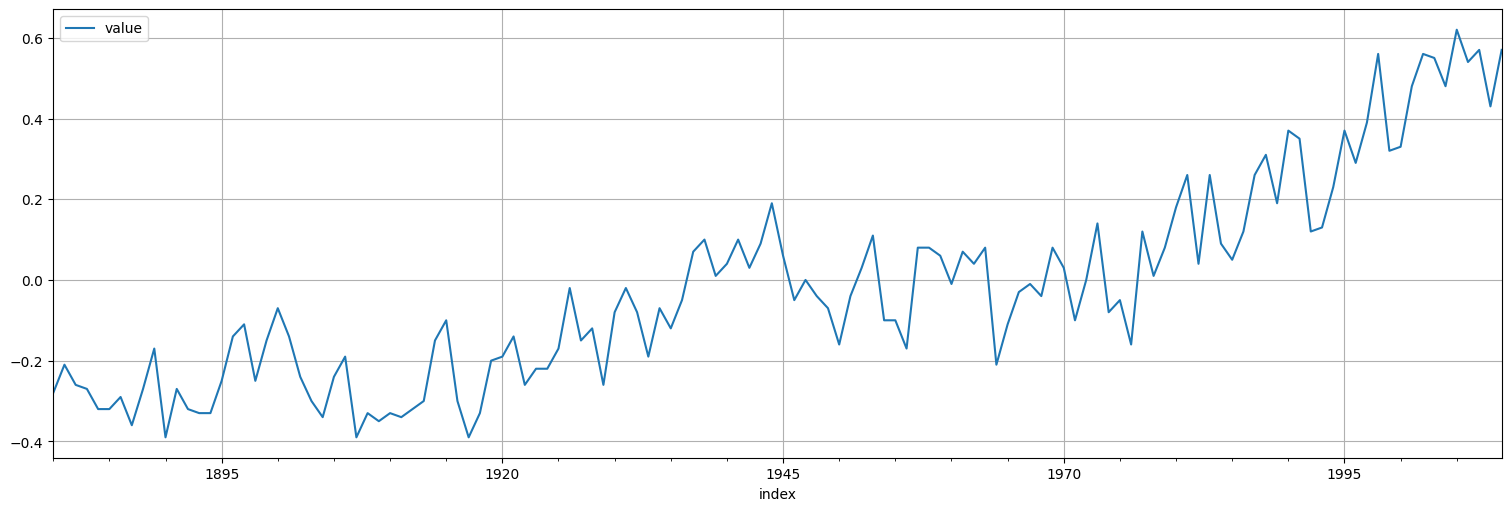
Aplicación a la serie de temperaturas globales.¶
Utilizando la serie gtemp de temperaturas globales ya vista anteriormente, ajustar un modelo \(ARIMA(p,d,q)\) adecuado utilizando las técnicas anteriores.
gtemp = astsa.gtemp
gtemp.plot();
Aplicación a la serie de pasajeros aéreos.¶
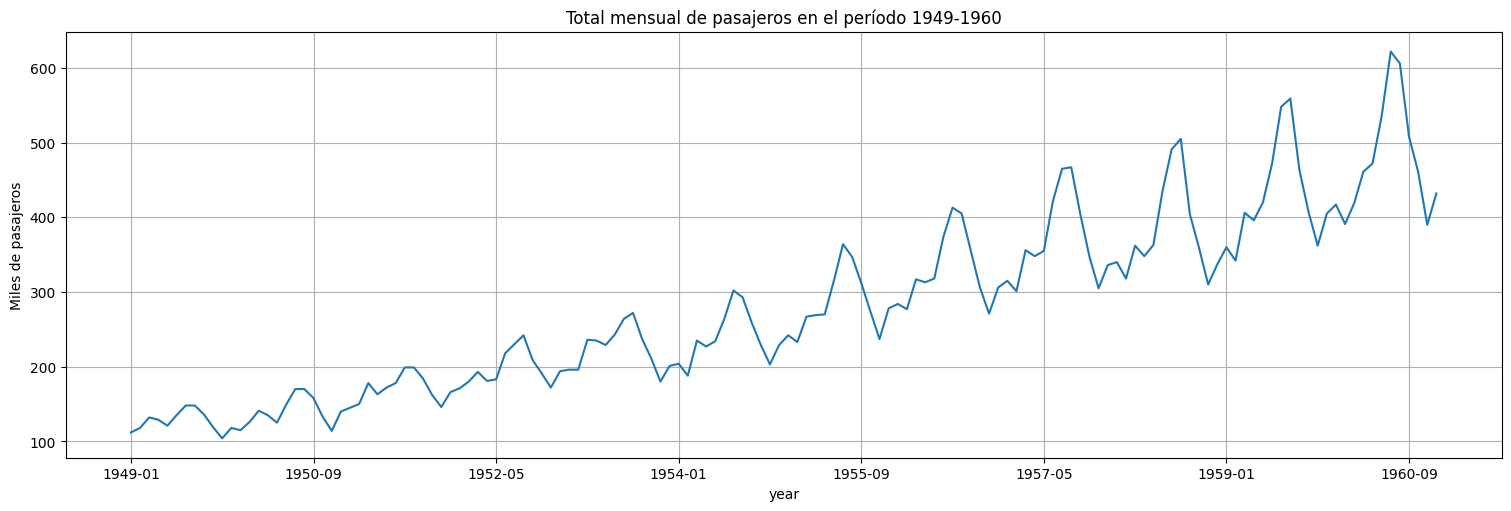
Utilizando la serie AirPassengers vista anteriormente, ajustar un modelo tipo \(SARIMA\) adecuado (diferenciando y transformando si es necesario) de estacionalidad \(12\). Comparar con los ajustes realizados previamente en base a senos y cosenos.
df = pd.read_csv('../data/international-airline-passengers.csv', names = ['year','passengers'], header=0)
air = pd.Series(df["passengers"].values, index=df['year'])
air.plot();
plt.title("Total mensual de pasajeros en el período 1949-1960")
plt.ylabel("Miles de pasajeros");