Regresión no lineal¶
Cuando el modelo es no lineal, ¿qué podemos hacer?
Ejemplo: En el caso de la combinación de \(\sin\) y \(\cos\) ya sabíamos la frecuencia, pero si la dejamos libre el modelo:
pasa a ser no lineal, con parámetros \(\theta=(\beta_1,\beta_2,f)\).
Ejemplo (Crecimiento logístico): En estudio de poblaciones, muchas veces es útil ajustar un modelo de la forma: $\(f(t;\theta) = \frac{A}{1+e^{-b(t-t_0)}}\)\( siendo los parámetros en este caso \)\theta=(A,b,t_0)$.
Idea: aplicar el mismo criterio de mínimos cuadrados¶
Es decir si tengo una función no lineal de los parámetros desconocidos \(y_t(\theta)\), buscamos resolver:
Problema: la optimización anterior no necesariamente es fácil de hacer. No hay garantías de convexidad, puede tener mínimos locales.
El algoritmo más utilizado para resolver el problema anterior es el de Gauss-Newton que converge a un mínimo local. Si tenemos una buena aproximación inicial de la solución converge.
Observación: La elección de la condición inicial es completamente dependiente del modelo utilizado. A veces es posible hacer una aproximación lineal de primer orden. Otra idea es utilizar propiedades de la función a ajustar para elegir buenas condiciones iniciales. También es buena idea “sacudir” un poco el proceso cambiando las condiciones para ver cuán robusto es el ajuste.
Ejemplo:¶
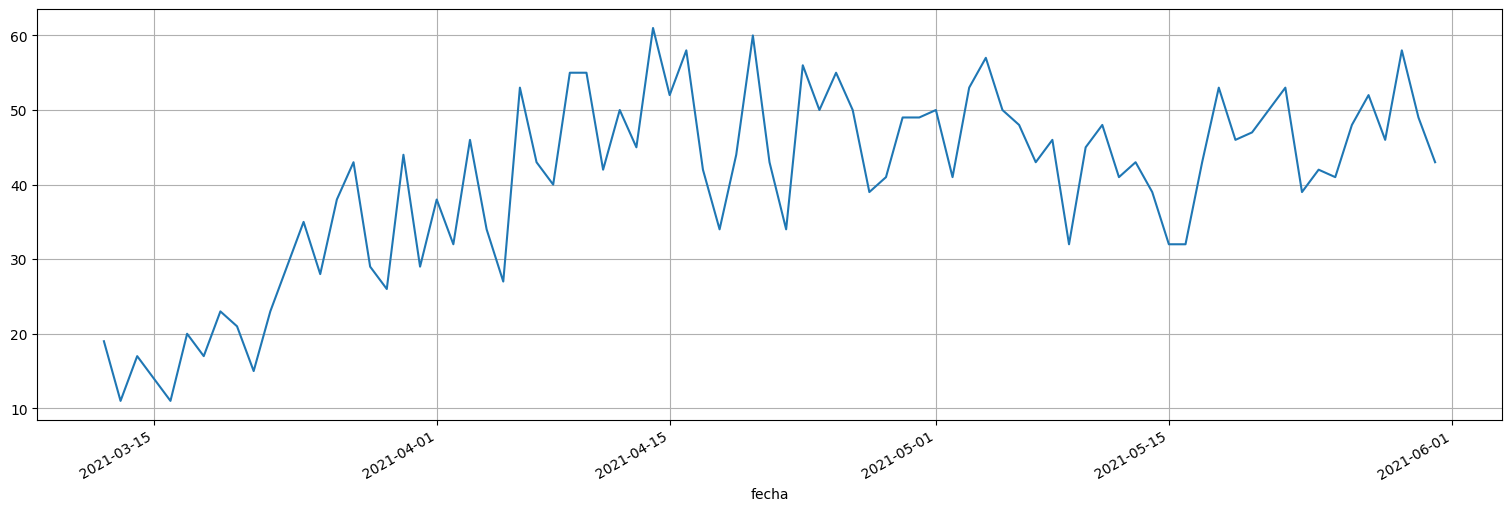
Analicemos los ingresos a CTI por COVID en Uruguay en el período 15/3 – 30/4.
import pandas as pd
datos = pd.read_csv("https://raw.githubusercontent.com/GUIAD-COVID/datos-y-visualizaciones-GUIAD/master/datos/estadisticasUY_cti.csv", header=0,
index_col=[1], parse_dates=[1], date_format="%d/%m/%Y")
cti = datos["ingresos"].iloc[40:120]
cti.plot();
Modelo:¶
Proponemos el siguiente modelo no lineal para ajustar una “meseta”:
siendo \(\theta = (a,b,c)\).
Implementación en Python¶
La biblioteca
scipyofrece una funciónscipy.optimize.least_squares. Recibe como input una función \(g(\theta)\) que a partir de los valores de los parámetros \(\theta\) devuelve el vector de residuos.Es decir, en nuestro caso debemos construir una función \(f(t,\theta)\) que evaúe la función no lineal a optimizar.
Luego realizar una función \(g\) que realice lo mismo evaluando \(f\) en cada valor de \(t\) y construya el vector:
Por último, se llama a
least_squarespasando como parámetros la función \(g\) y la condición inicial de búsqueda \(\theta_0\).
def f(theta, t):
return theta[0] + theta[1]*np.exp(- theta[2] * t)
ts = np.arange(0,cti.size)
xs = cti.values
#En la implementación le llamamos residuos a la función g anterior
def residuos(theta):
return f(theta, ts) - xs
from scipy.optimize import least_squares
theta0 = [50,-50,0.1]
fit = least_squares(residuos, theta0)
#Mostramos el resultado del fit
fit
message: `ftol` termination condition is satisfied.
success: True
status: 2
fun: [-1.095e+01 4.504e-02 ... -1.880e+00 4.126e+00]
x: [ 4.720e+01 -3.915e+01 7.958e-02]
cost: 2136.5518731435595
jac: [[ 1.000e+00 1.000e+00 0.000e+00]
[ 1.000e+00 9.235e-01 3.615e+01]
...
[ 1.000e+00 2.015e-03 6.151e+00]
[ 1.000e+00 1.860e-03 5.754e+00]]
grad: [-5.691e-06 -2.108e-07 9.776e-01]
optimality: 0.9776031482176677
active_mask: [ 0.000e+00 0.000e+00 0.000e+00]
nfev: 11
njev: 11
Resultados¶
Del fit anterior podemos extraer los coeficientes y el error.
a = fit.x[0]
b = fit.x[1]
c = fit.x[2]
#Least squares usa como loss 1/2 de la suma de los residuos
#por lo que a fit.cost hay que multiplicarlo por dos para obtener la suma de cuadrados
MSE_fit = 2*fit.cost/xs.size
print("Coeficientes estimados:")
print(f"a = {a}")
print(f"b = {b}")
print(f"c = {c}")
print(f"Mean square error: {MSE_fit}")
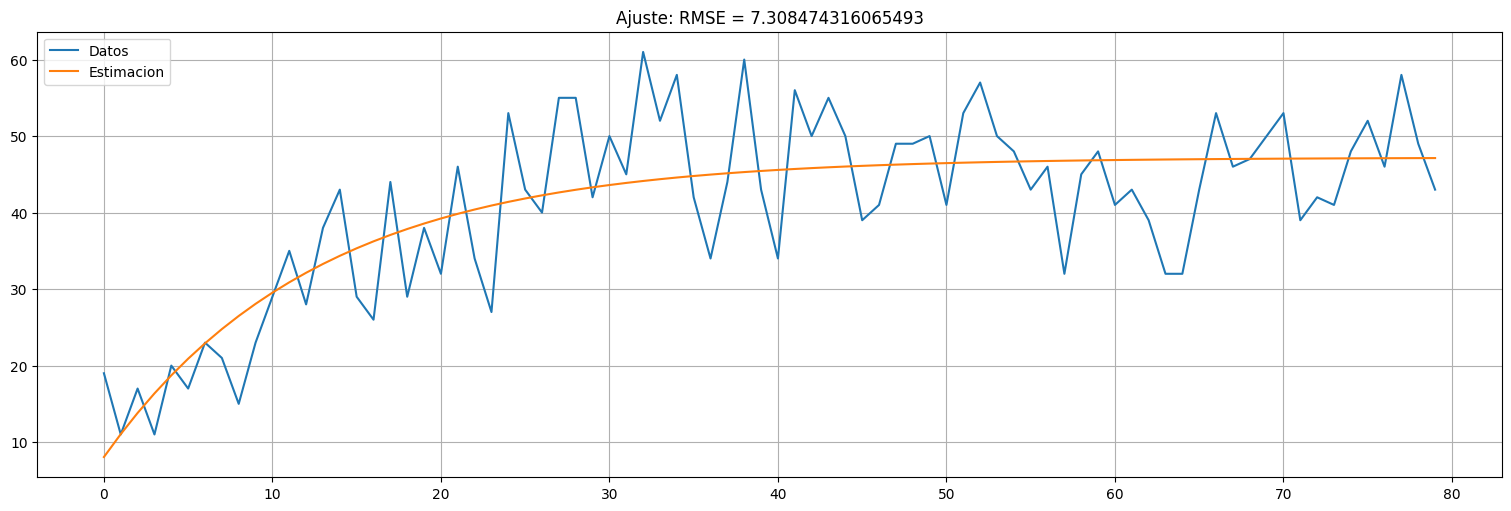
Coeficientes estimados:
a = 47.19848397604239
b = -39.148174713716685
c = 0.07958170675096753
Mean square error: 53.413796828588985
plt.plot(ts,xs, label="Datos");
plt.plot(ts,f(fit.x,ts), label="Estimacion")
plt.legend();
plt.title(f"Ajuste: RMSE = {np.sqrt(MSE_fit)}");
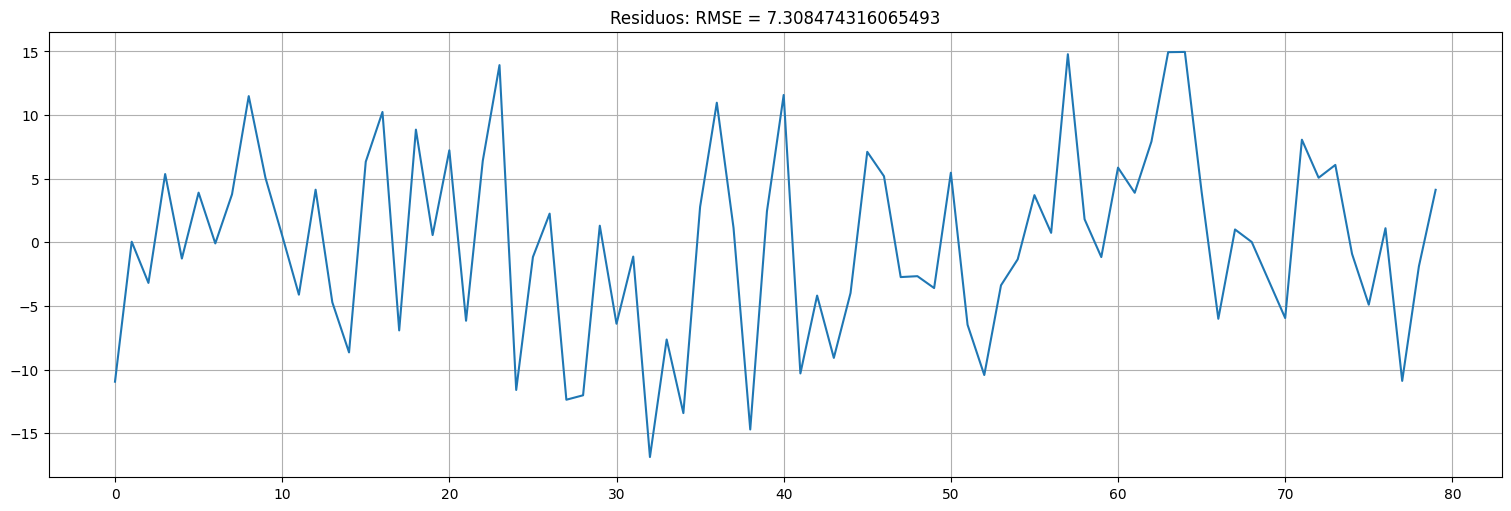
#en fit.fun me guarda los residuos que alcanzan el mínimo.
#es equivalente a evaluar la función ajustada y restarle la serie original.
residuos = fit.fun
plt.plot(ts,residuos);
plt.title(f"Residuos: RMSE = {np.std(residuos)}"); #o bien sqrt(loss) debería dar lo mismo
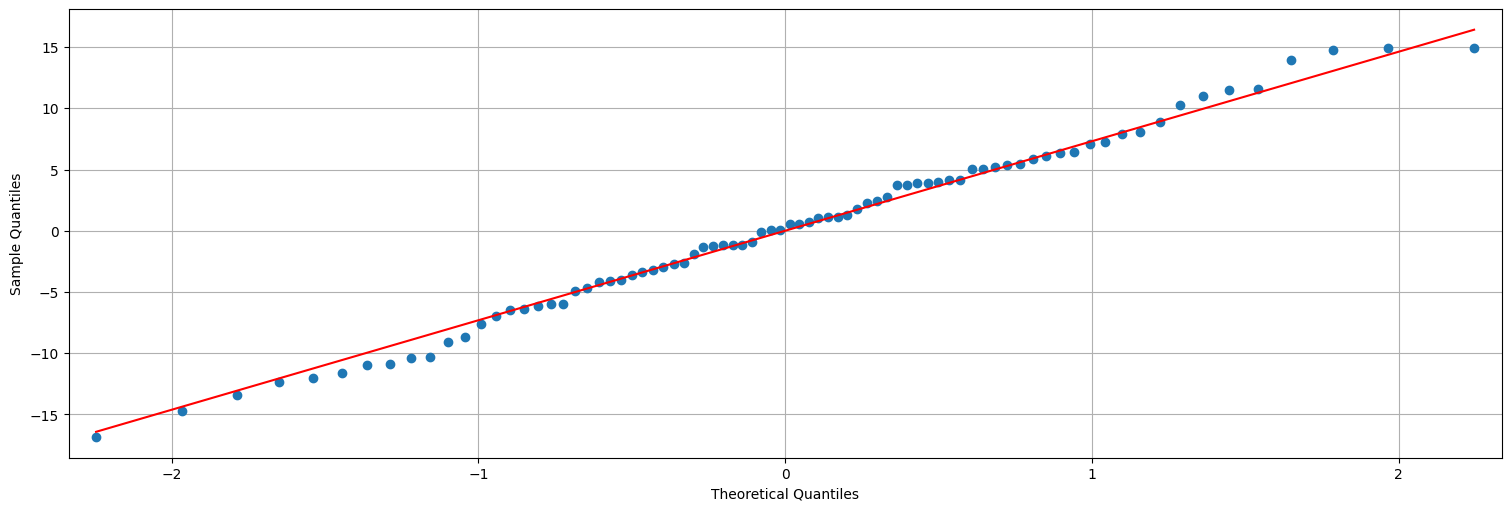
sm.qqplot(residuos, line="s");
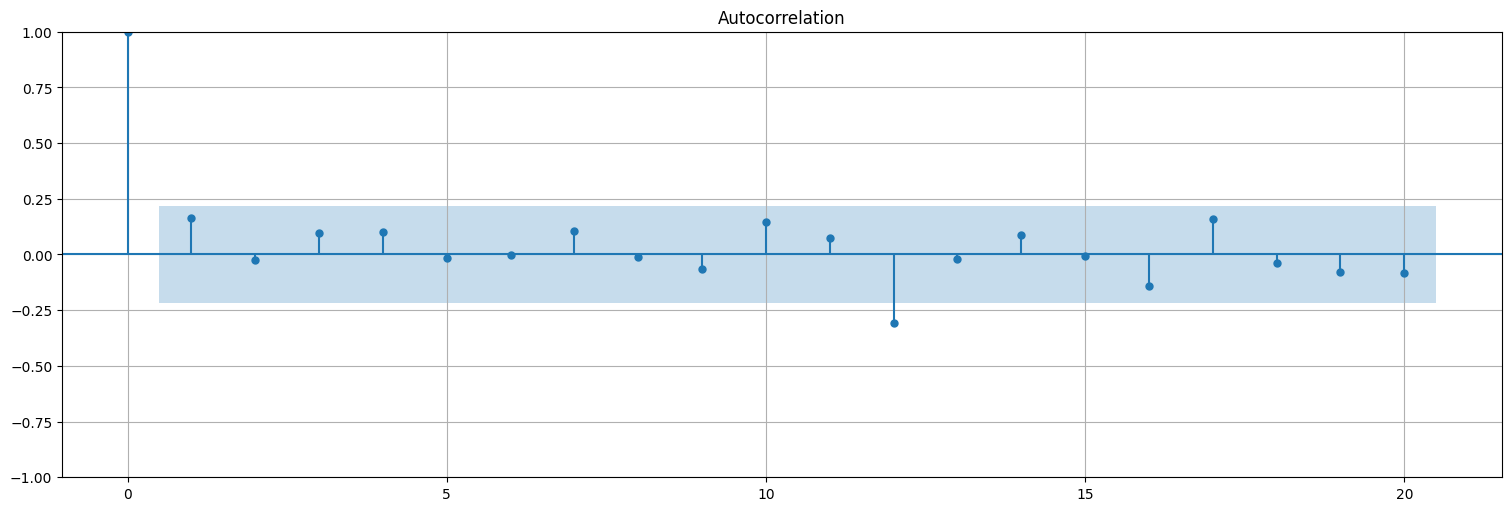
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(residuos, bartlett_confint=False);
#Calculo el R^2
n=cti.size
RSS = np.sum(residuos**2)/n
SSE = np.sum((cti-np.mean(cti))**2)/n
R2 = (SSE-RSS)/SSE
print(f"RSS = {RSS}");
print(f"SSE = {SSE}");
print(f"R2 = {R2}");
RSS = 53.413796828588985
SSE = 142.82734375
R2 = 0.6260254134384615
Ejercicio¶
Curva de población logística¶
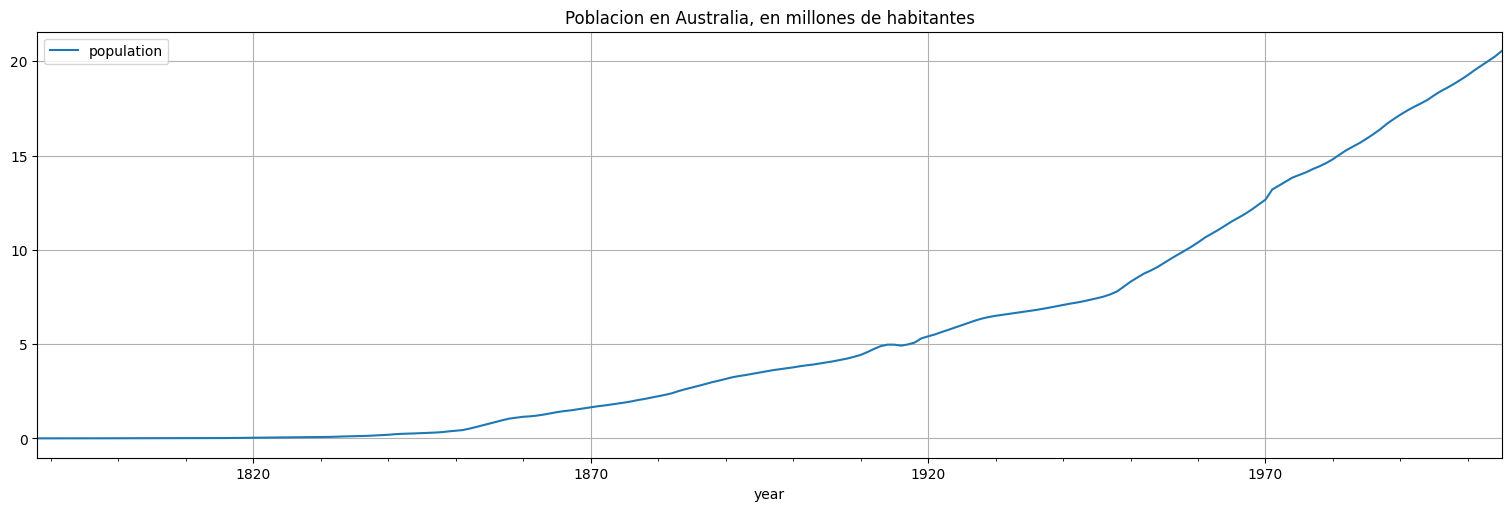
Realice un ajuste de curva logística a la serie de poblaciones de Australia entre 1778 y 2005 almacenada en data/au_population.csv.
La función logística de parámetros \(A\), \(b\) y \(t_0\) tiene la siguiente expresión:
Los parámetros representan:
\(A\): el valor asintótico.
\(b\): la velocidad de transición de \(0\) a \(A\).
\(t_0\): el tiempo de transición (donde vale \(A/2\)).
pop = pd.read_csv("../data/au_population.csv", header=0,
index_col=[0], parse_dates=[0], date_format="%Y")
pop = pop/1e6
pop.tail(6)
| population | |
|---|---|
| year | |
| 2000-01-01 | 19.272644 |
| 2001-01-01 | 19.533972 |
| 2002-01-01 | 19.770963 |
| 2003-01-01 | 20.011882 |
| 2004-01-01 | 20.252132 |
| 2005-01-01 | 20.544064 |
pop.plot(title="Poblacion en Australia, en millones de habitantes");