Medidas de dependencia: covarianza, autocorrelación y correlación cruzada.¶
Variables aleatorias conjuntas.¶
Cuando definimos espacio muestral, comentamos que \(\Omega\) tiene “todo lo que puede pasar” en nuestro experimento. Ahora, podemos tener varias variables aleatorias que surjan como medidas de realizar el mismo experimento. En este caso las v.a. están definidas sobre un mismo espacio de probabilidad y se denominan v.a. conjuntas.
Ejemplo:
Experimento: extraer una persona al azar de la población
Variables: \(X=\) altura, \(Y=\) peso de la persona.
Podría también tomarse \(Z=\) índice de masa corporal \(=Y/X^2 = g(X,Y)\), una tercera v.a. que es función de las anteriores.
Función de densidad conjunta¶
Cuando las variables se comportan de manera conjunta, la noción de densidad es más complicada. Es una función de todas las posibles combinaciones de valores \((x_1,\ldots,x_n)\):
Definición: Una conjunto de variables aleatorias \((X_1,\ldots,X_n)\) tiene densidad conjunta \(f(x_1,\ldots,x_n)\) si y solo si para toda región \(R\subset \mathbb{R}^n\):
\[ P(X \in R) = \int\cdots\int_R f(x_1,\ldots,x_n)dx_1\ldots dx_n\]
La función \(f\) de densidad me indica como se reparte la masa en el espacio \((x_1,\ldots,x_n)\). Normalmente esto lo visualizamos haciendo “nubes de puntos” con muestras de la variable conjunta.
Densidad Marginal¶
Si dos variables (o más) tienen densidad conjunta \(f(x,y)\), se pueden obtener sus densidades marginales, es decir, la de cada una por separado. Se hace integrando sobre todos los posibles valores de la(s) otra(s) variables.
Por ejemplo, si \((X,Y)\sim f(x,y)\) entonces:
Ejemplo: variables uniformes independientes¶
Supongamos que elegimos puntos al azar completamente en el cuadrado \([0,1]\times[0,1]\). Esto corresponde a sortear de manera uniforme sus coordenadas.
## sorteo uniforme las coordenadas
X=np.random.uniform(size=100) #500 puntos entre 0 y 1 uniformes
Y=np.random.uniform(size=100) #500 puntos más para la otra coordenada
plt.figure(figsize=(5,5))
plt.scatter(X,Y)
plt.axis("equal"); #dibuja ambas componentes en la misma escala
Histogramas:
plt.subplot(1,2,1)
plt.hist(X)
plt.title(r"Histograma de $X$")
plt.subplot(1,2,2)
plt.hist(Y)
plt.title(r"Histograma de $Y$");
Media y varianza¶
La media y varianza de variables se definen como antes, usando las marginales:
Y en general para cualquier función \(g:\mathbb{R}^2\to \mathbb{R}\) que dependa de ambas variables:
Independencia de variables aleatorias¶
Dos variables son independientes si y solo si conocer el valor de una no afecta la distribución de la otra variable. Es decir, saber el resultado de una no cambia mi percepción sobre la otra, sigue teniendo la misma distribución que antes.
Esto se cumple si y solo si vale la siguiente regla producto:
En ese caso, \(P(X\in A,Y\in B) = P(X\in A)P(X\in B)\) para cualquier suceso \(A,B\) y en particular:
que es lo que pide la definición.
Ejemplo: variables no independientes¶
En el ejemplo de las coordenadas en \([0,1]\times[0,1]\) precisamente sorteamos \(X\) e \(Y\) de manera independiente, por lo cual saber la coordenada \(X\) no cambia mi percepción sobre la coordenada \(Y\) (sigue siendo Uniforme en [0,1]).
Veamos ejemplos donde esto no ocurre, es decir que hay información cruzada.
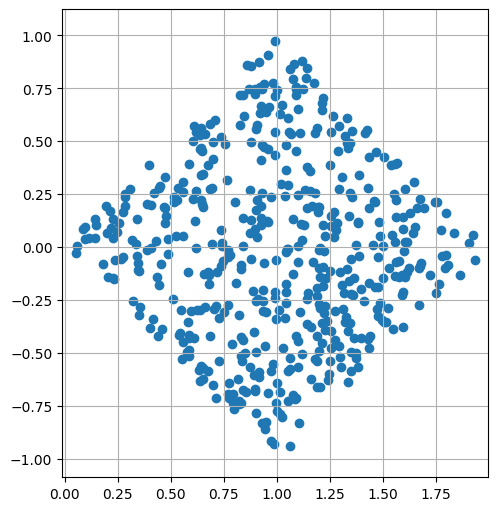
Para ello, tomemos una transformación de los puntos anteriores:
¿Estas variables serán independientes?
## sorteo uniforme las coordenadas
X=np.random.uniform(size=500) #500 puntos entre 0 y 1 uniformes
Y=np.random.uniform(size=500) #500 puntos más para la otra coordenada
U=X+Y
V=X-Y
plt.figure(figsize=(5,5))
plt.scatter(U,V)
plt.axis("equal"); #dibuja ambas componentes en la misma escala
Histogramas:
plt.subplot(1,2,1)
plt.hist(U)
plt.title(r"Histograma de $U$")
plt.subplot(1,2,2)
plt.hist(V)
plt.title(r"Histograma de $V$");
¿Por qué no son independientes?
Las variables \(U\) y \(V\) así construidas tienen una distribución marginal en forma de triángulo.
La suma \(U\) va entre \(0\) y \(2\) con valor más probable \(1\).
La resta \(V\) va entre \(-1\) y \(1\) con valor más probable \(0\).
Además no son independientes: observemos tanto \(X\) como \(Y\) participan en la construcción de \(U\) y \(V\) por lo que es de esperar que esto ocurra.
En particular que si sabemos que \(U\) es grande (la suma está cerca de \(2\)) entonces tanto \(X\) como \(Y\) tienen que estar cerca de \(1\), por lo que su diferencia debe estar cerca de \(0\)!!!!
De este modo hay información cruzada.
Covarianza: una medida de dependencia.¶
Dadas dos variables aleatorias \(X\) e \(Y\) conjuntas, definimos la covarianza entre ellas como:
Es decir, cuánto varía en promedio el producto de los desvíos respecto a la media.
Idea:
Si dos variables están asociadas de modo que valores altos de una (respecto a su media) producen valores altos de la otra (respecto a su media), tendrán covarianza alta y positiva.
Si dos variables están asociadas negativamente, es decir, valores altos de una (respecto a su media) produce valores bajos de la otra (respecto a su media), tendrán covarianza alta y negativa.
Si dos variables son independientes, su covarianza será 0.
Si tenemos \((X_1,\ldots,X_n)\) conjuntas, a la matriz \(\Sigma\) de todas las covarianzas entre ellas se le llama matriz de covarianzas. En la diagonal tenemos \(\mathrm{Cov}(X_i,X_i) = \mathrm{Var}(X_i)\).
Propiedad de la covarianza (combinaciones lineales):
Si \(U = \sum_{j=1}^m a_j X_j\) y \(V = \sum_{k=1}^n b_k Y_k\) son v.a. que resultan de combinar linealmente \(\{X_j:j=1,\ldots,m\}\) y \(\{Y_k:k=1\ldots,n\}\) entonces:
Observar que lo anterior puede ponerse como \(\textrm{Cov}(U,V) = a^T \Sigma b\) siendo \(a\) y \(b\) vectores columna y \(\Sigma\) una matriz \(m\times n\) cuyas entradas son las covarianzas.
En particular, si \(X\) es un vector aleatorio con matriz de covarianzas \(\Sigma\), y \(U=a^T X\), \(\textrm{Var}(U) = a^T \Sigma a\) (interpretando \(a\) como vector columna).
Ejemplo:
Si quiero calcular \(\textrm{Cov}(X+Y, X-Y)\) tengo que hacer:
en este caso.
Coeficiente de correlación¶
La covarianza tiene las mismas unidades que la varianza, y puede ser más grande o más chica dependiendo de la variabilidad intrínseca de \(X\) e \(Y\). Es por eso que se define el coeficiente de correlación:
Este tiene las siguientes propiedades:
\(-1\leqslant \rho(X,Y)\leqslant 1\).
Si \(X,Y\) independientes, \(\rho(X,Y)=0\).
\(\rho(X,Y) = 1\) si y solo si \(Y = aX+b\) para cierto \(a>0\) y \(b\in \mathbb{R}\).
\(\rho(X,Y) = -1\) si y solo si \(Y = aX+b\) para cierto \(a<0\) y \(b\in \mathbb{R}\).
Ejemplo¶
Estimemos la covarianza a partir de los datos y el coeficiente de correlación para las coordenadas \((X,Y)\) sorteadas anteriormente:
print("La covarianza es:")
print(np.cov(X,Y))
print("La correlación es:")
print(np.corrcoef(X,Y))
La covarianza es:
[[ 0.08386667 -0.00236227]
[-0.00236227 0.08529627]]
La correlación es:
[[ 1. -0.02792991]
[-0.02792991 1. ]]
Ejemplo¶
¿Qué ocurre si lo hacemos para \(U\) y \(V\), los transformados?
print("La covarianza es:")
print(np.cov(U,V))
print("La correlación es:")
print(np.corrcoef(U,V))
La covarianza es:
[[ 0.1644384 -0.0014296 ]
[-0.0014296 0.17388747]]
La correlación es:
[[ 1. -0.00845433]
[-0.00845433 1. ]]
Observación: baja correlación no implica independencia!!!! Pero independencia implica baja correlación (0).
Ejemplo: vectores aleatorios Gaussianos.¶
Un vector aleatorio Gaussiano \(X=(X_1,\ldots,X_n)\) es la generalización de la distribución normal a múltiples dimensiones. Está caracterizado por:
Un vector de medias \(\mu\) que dice el centro de cada una de las coordenadas.
Una matriz de covarianzas \(\Sigma\) que tiene:
En la diagonal, las varianzas de cada componente.
Fuera de la diagonal, la covarianza de cada par de coordenadas (por lo tanto es simétrica).
En numpy podemos sortear vectores gaussianos usando la función np.random.multivariate_normal().
Ejemplo
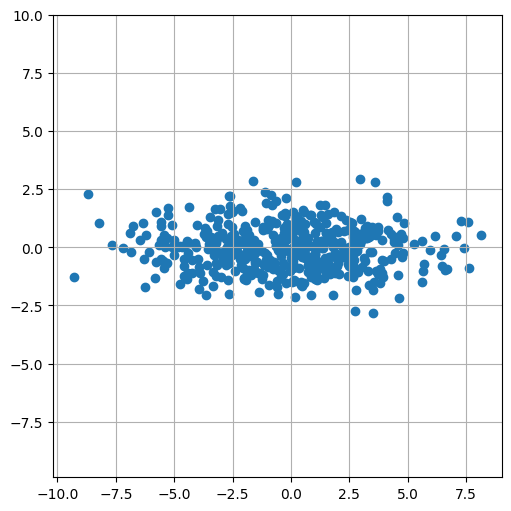
Tomemos dos variables con \(\mu=(0,0)\) (centradas) y con matriz de covarianzas:
Es decir, la primera componente tiene más varianza que la segunda, y su covarianza es \(0\).
mu = np.array([0,0])
Sigma = np.matrix([[9,0],[0,1]])
X = np.random.multivariate_normal(mean=mu, cov=Sigma, size=500)
plt.figure(figsize=(5,5))
plt.scatter(X[:,0], X[:,1])
plt.axis("equal");
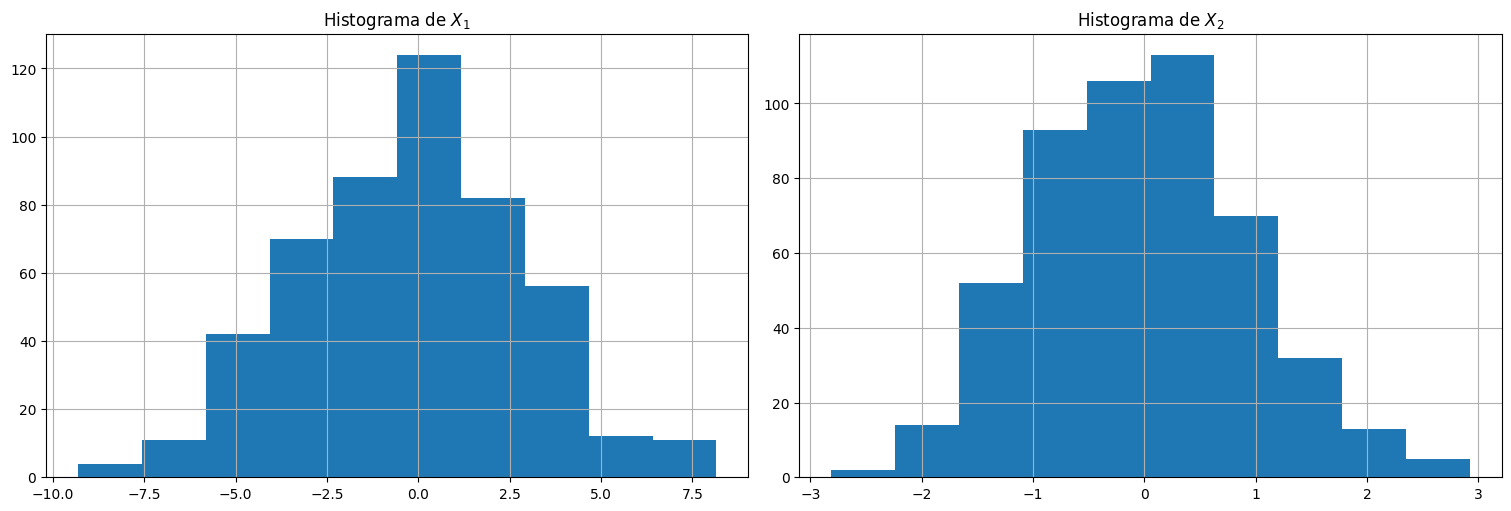
plt.subplot(1,2,1)
plt.hist(X[:,0])
plt.title(r"Histograma de $X_1$")
plt.subplot(1,2,2)
plt.hist(X[:,1])
plt.title(r"Histograma de $X_2$");
print(f"Media de X_1 = {np.mean(X[:,0])}")
print(f"Media de X_2 = {np.mean(X[:,1])}")
print(f"Varianza de X_1 = {np.var(X[:,0])}")
print(f"Varianza de X_2 = {np.var(X[:,1])}")
print(f"La Covarianza es:")
print(np.cov(X[:,0], X[:,1]))
print(f"La correlación es es:")
print(np.corrcoef(X[:,0], X[:,1]))
Media de X_1 = -0.20120016375895258
Media de X_2 = -0.018832990336931473
Varianza de X_1 = 9.397103002967055
Varianza de X_2 = 0.9312831950391468
La Covarianza es:
[[ 9.41593487 -0.09330451]
[-0.09330451 0.93314949]]
La correlación es es:
[[ 1. -0.03147714]
[-0.03147714 1. ]]
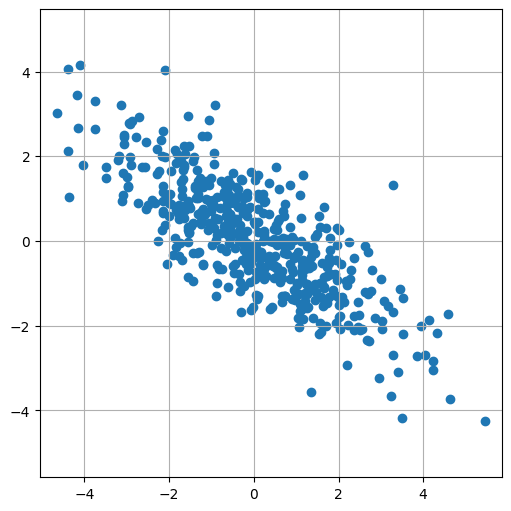
Ejemplo:
Tomemos dos variables con \(\mu=(0,0)\) (centradas) y con matriz de covarianzas:
Las varianzas son más parecidas entre sí y tienen correlación negativa.
mu = np.array([0,0])
Sigma = np.matrix([[3,-2],[-2,2]])
X = np.random.multivariate_normal(mean=mu, cov=Sigma, size=500)
plt.figure(figsize=(5,5))
plt.scatter(X[:,0], X[:,1])
plt.axis("equal");
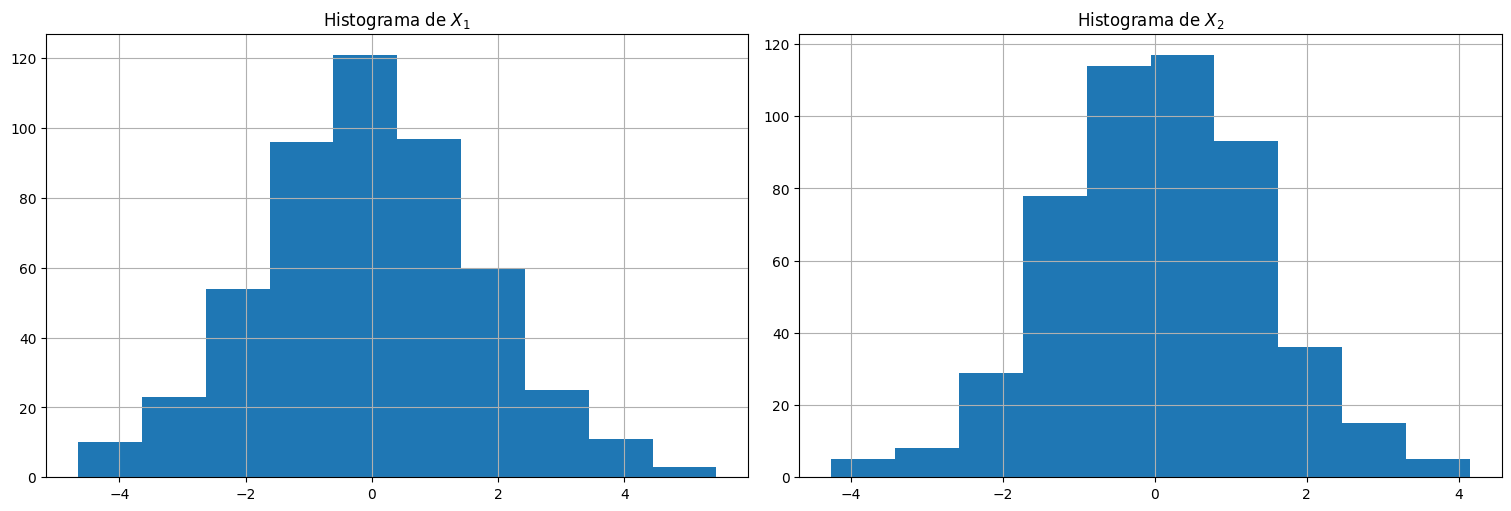
plt.subplot(1,2,1)
plt.hist(X[:,0])
plt.title(r"Histograma de $X_1$")
plt.subplot(1,2,2)
plt.hist(X[:,1])
plt.title(r"Histograma de $X_2$");
print(f"Media de X_1 = {np.mean(X[:,0])}")
print(f"Media de X_2 = {np.mean(X[:,1])}")
print(f"Varianza de X_1 = {np.var(X[:,0])}")
print(f"Varianza de X_2 = {np.var(X[:,1])}")
print(f"La Covarianza es:")
print(np.cov(X[:,0], X[:,1]))
print(f"La correlación es es:")
print(np.corrcoef(X[:,0], X[:,1]))
Media de X_1 = -0.021922363590680775
Media de X_2 = 0.05823511092323803
Varianza de X_1 = 2.9593028010054385
Varianza de X_2 = 1.7845437735411147
La Covarianza es:
[[ 2.96523327 -1.80925997]
[-1.80925997 1.78812001]]
La correlación es es:
[[ 1. -0.78572977]
[-0.78572977 1. ]]
Definición de serie temporal:¶
Una serie temporal es una sucesión de variables aleatorias o proceso estocástico \(x_0,x_1,x_2,\ldots\) definidas en un espacio de probabilidad \((\Omega,\mathcal{A},P)\). La variable aleatoria \(x_t\) denota el valor del proceso al tiempo \(t\).
Al proceso estocástico o serie temporal se lo denota por \(\{x_t\}\).
Típicamente (y para todo este curso) se consideran indexados por \(t\) entero (\(\ldots, -2, -1, 0, 1, 2, \ldots\)).
A los valores particulares que toma una serie temporal cuando la observamos se le denomina realización del proceso, y lo denotaremos por \(x_t\), abusando un poco de la notación.
Observación: Como ahora tenemos una v.a. para cada momento del tiempo, tanto la media como la varianza del proceso pueden cambiar en el tiempo.
Función media de una serie temporal¶
Definición: La función media (mean function) de un proceso estocástico o serie temporal \(\{x_t\}\) se define como:
Notar que en principio depende del tiempo.
Ejemplo: Ruido blanco¶
Si \(x_t = w_t\) ruido blanco Gaussiano, entonces \(E[w_t] = 0\) por lo que \(\mu_t = 0\) para todo \(t\).
w = np.random.normal(size=1000,loc=0,scale=1) # 1000 N(0,1) variates
plt.plot(w)
plt.axhline(y=0, color='b')
plt.title(r"Ruido Blanco Gaussiano $w(t)$");
Ejemplo: Media móvil¶
Si \(w_t\) es ruido blanco Gaussiano y definimos el proceso de media móvil:
Entonces \(E[x_t] = \frac{1}{3}[E[w_{t-2}] + E[w_{t-1}] + E[w_t] = 0\) por lo que también \(\mu_t = 0\) para todo \(t\).
n=3
x = sp.signal.lfilter(1/n*np.ones(n),1,w) #Aplica el filtro de media móvil
plt.plot(x, label=r"$x(t)$");
plt.axhline(y=0, color='b')
plt.legend();
Ejemplo: Paseo al azar con deriva¶
Si el proceso es:
con \(\{w_j\}\) ruido blanco, entonces \(\mu_t = E[x_t] = \delta t\).
Ejemplo: Señal más ruido.¶
Si el proceso es de la forma:
con \(s_t\) una señal dada (ej: función coseno del ejemplo del cuaderno anterior), y \(w_t\) ruido de media \(0\), entonces \(E[x_t] = s_t\).
Observaciones:¶
El comportamiento completo de un proceso estocástico queda definida por toda la familia de distribuciones conjuntas de las variables que lo integran \(\{x_t\}\).
Dichas distribuciones deben ser consistentes entre sí (muy difícil de chequear).
En general es muy difícil trabajar con la distribución conjunta salvo casos excepcionales (ej: Gaussiana)
La distribución marginal de \(x_t\) solo nos dice cómo se comporta el proceso en tiempo \(t\), pero no su interrelación con los demás tiempos.
¿Cómo podemos medir la relación de los valores del proceso en diferentes momentos del tiempo?
Autocovarianza de una serie temporal¶
La autocovarianza es una medida de la estructura de dependencia interna del proceso.
Definición: La función de autocovarianza de una serie temporal es la covarianza entre dos instantes de tiempo:
\[\gamma_x(s,t) = \textrm{Cov}(x_s,x_t) = E[(x_s-\mu_s)(x_t-\mu_t)].\]para cada \(s\) y \(t\).
Propiedades:
Para \(s=t\), \(\gamma_x(s,s) = \textrm{Cov}(x_s,x_s) = \textrm{Var}(x_s)\).
\(\gamma_x(s,t) = \gamma_x(t,s)\) por definición por lo que la función es simétrica.
Si \(\gamma(s,t) = 0\) quiere decir que no hay dependencia lineal (pero no que son independientes).
Si \(\gamma(s,t) = 0\) y \(x_s,x_t\) son conjuntamente Gaussianos, entonces \(x_s\) y \(x_t\) son independientes.
Ejemplo: Ruido blanco¶
Si \(x_t = w_t\) ruido blanco, por definición \(w_s\) y \(w_t\) son no correlacionados, es decir \(\textrm{Cov}(w_s,w_t) = 0\). A su vez, a \(\textrm{Cov}(w_s,w_s) = \textrm{Var}(w_s) = \sigma^2_w\) se le denomina potencia del ruido blanco.
Por lo tanto:
Ejemplo: Media móvil¶
Considere nuevamente proceso de media móvil:
Aplicando la propiedad de combinaciones lineales citada antes se obtiene:
Notar que en los dos casos anteriores, \(\gamma(s,t)\) solo depende de \(t-s\), el intervalo de tiempo entre las observaciones.
Ejemplo: Paseo al azar¶
Consideremos un paseo al azar sin deriva \(x_t = \sum_{j=1}^t w_j\) con \(\{w_j\}\) ruido blanco. La autocovarianza queda:
Prueba: usar la propiedad de combinaciones lineales y contar la cantidad de términos que sobreviven usando que \(\textrm{Cov}(w_s,w_t)=0\) si \(s\neq t\).
Observar que en este caso \(\gamma_x\) depende explícitamente de \(s\) y \(t\) (no solo la diferencia) y que \(\textrm{Var}(x_t) = t\sigma_w^2\) es creciente con \(t\) (porque acumulamos más términos).
#Paseo al azar sin deriva
w = np.random.normal(size=500,loc=0,scale=1)
x = np.cumsum(w)
plt.plot(x)
plt.title("Varias realizaciones de un paseo al azar sin deriva")
#agrego mas realizaciones
for i in range(1,20):
w = np.random.normal(size=500,loc=0,scale=1)
x = np.cumsum(w)
plt.plot(x,alpha=0.3)
plt.plot(ylims=(-10,10));
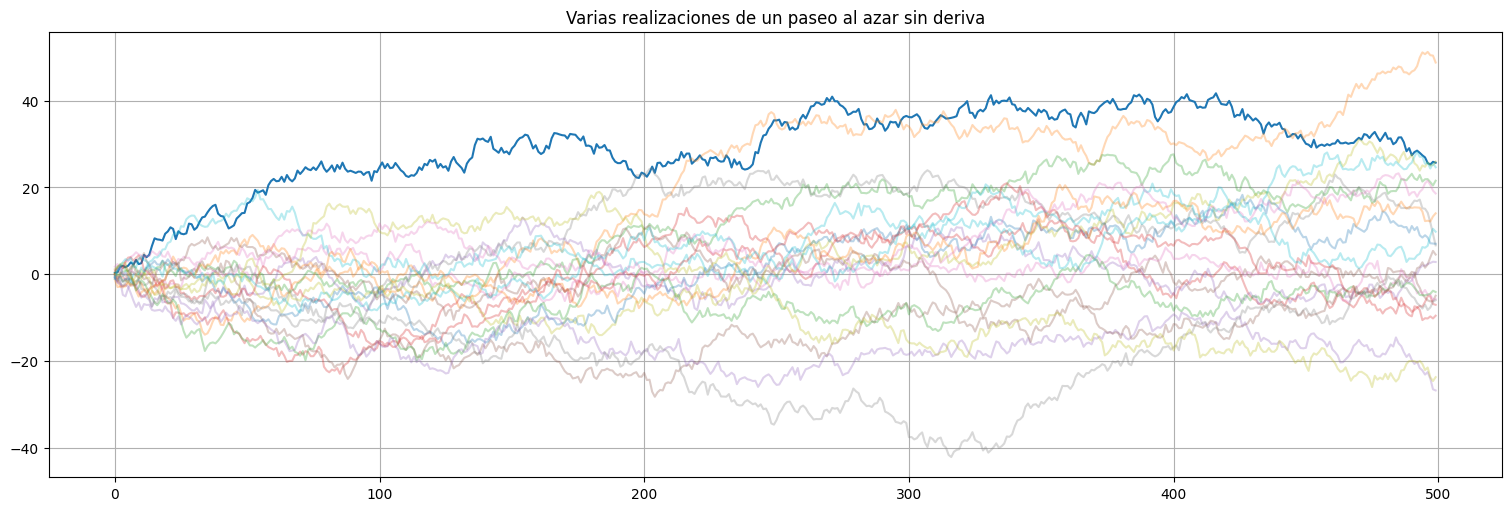
Autocorrelación de una serie temporal¶
Como la covarianza depende de la escala del proceso, conviene también definir:
Definición: La función de autocorrelación (ACF) de un proceso o serie de tiempo \(x_t\) se define como:
\[ \rho(s,t) = \frac{\gamma(s,t)}{\sqrt{\gamma(s,s)\gamma(t,t)}}.\]
Nuevamente, mide la relación lineal de la serie en tiempo \(t\) a partir de su valor en \(s\).
Igual que antes, se cumple que \(-1\leq \rho(s,t) \leq 1\) para todo \(s,t\). Si \(x_t = ax_s+b\), entonces \(\rho\) es \(1\) o \(-1\) dependiendo del signo de \(a\).
Ejemplo: Media móvil¶
Volvamos al proceso de media móvil:
del cual ya calculamos la covarianza. También sabemos que \(\gamma(t,t) = 3/9 \sigma_w^2\) pues así lo calculamos para \(s=t\). Por lo tanto:
Notar que nuevamente \(\rho(s,t)\) solo depende de \(t-s\) y a su vez ahora es independiente del tamaño del ruido.
Correlación cruzada de series.¶
La idea aquí es definir la misma idea de correlación de una serie pero para relacionar una serie \(\{x_t\}\) con otra \(\{y_t\}\).
Definición: La covarianza cruzada (o cross-covariance) de dos series se define como:
Definición: La correlación cruzada (o cross-correlation) de dos series se define como:
Procesos estacionarios¶
Las definiciones anteriores son para cualquier proceso. Nos interesa en particular aquellos procesos que no cambian sus características en la ventana de tiempo que se miran. Dichos procesos se dicen estacionarios.
Definición: Un proceso se dice estacionario (en sentido estricto) si la función de distribución conjunta de \(\{x_{t_1},\ldots,x_{t_k}\}\) es idéntica a la de \(\{x_{t_1+h},\ldots,x_{t_k+h}\}\), para cualquier selección de los tiempos \(t_i\), cualquier \(k\) y \(h\) enteros.
Observación: muy difícil de chequear. En particular, la media \(\mu\) debe ser constante, así como la varianza y la distribución marginal de \(x_t\) en todo momento del tiempo.
Propiedad de los procesos estacionarios:¶
Una propiedad importante es la siguiente: si \(\{x_s,x_t\}\) tiene la misma distribución que \(\{x_{s+h},x_{t+h}\}\) entonces la autocovarianza debe cumplir
para todo \(h\). En particular, tomando \(h=-s\):
Es decir la autocovarianza solo depende del lag \(h=t-s\), la distancia entre las muestras.
Procesos estacionarios en sentido débil¶
Un proceso estocástico o serie temporal \(\{x_t\}\) se dice estacionaria (en sentido débil, pero diremos estacionaria de aquí en más) si se cumple que:
La media \(\mu_t = E[x_t] = \mu\) es constante para todo \(t\).
La autocovarianza \(\gamma(s,t)\) solo depende de \(s\) y \(t\) a través de su diferencia \(|t-s|\). En general la denotaremos como \(\gamma(h)\) siendo \(h\) el lag. Observar que \(\gamma(-h) = \gamma(h)\) y \(\gamma(0)=\textrm{Var}(x_t)\).
Observación: Estacionario estricto \(\Rightarrow\) estacionario.
Función de autocorrelación de un proceso estacionario.¶
Se define como:
Notar que la función es simétrica y \(\rho(0)=1\).
Estacionariedad conjunta¶
Dos series temporales son conjuntamente estacionarias si cada una es estacionaria y la función de covarianza cruzada (cross-covariance) solo depende del lag \(h\):
La función de correlación cruzada se define entonces de manera análoga:
Ejemplos:¶
El ruido blanco del ejemplo anterior.
La media móvil del ejemplo anterior.
Un proceso autorregresivo en estado estacionario, es decir, una vez que se olvidó de la condición inicial
NO SON EJEMPLOS: el paseo al azar (con o sin deriva). Señal escondida en el ruido.
Estimación de la correlación a partir de muestras¶
Problema: La función de autocorrelación está bien definida, pero si no tenemos el modelo debemos estimarla a partir de observaciones.
Desafío: en el caso de variables \(iid\) promediando podíamos hallar media y varianza. El problema aquí es que en general disponemos de una única realización de la serie de tiempo!
Idea: En el caso de series estacionarias, podemos utilizar las propias muestras, ya que las características de la serie no cambian con el tiempo.
Estimador de la media:¶
Sea \(x_t\) un proceso estacionario. Se tiene el siguiente estimador para la media \(\mu\):
La varianza de este estimador se puede calcular a partir de la correlación del proceso:
Estimador de la autocorrelación:¶
La autocovarianza muestral de una realización \(\{x_t\}\) de una serie de tiempo estacionaria se define como:
con \(\hat{\gamma}(-h) = \hat{\gamma}(h)\) y \(h=0,1\ldots,n-1\).
La autocorrelación muestral se define como:
Propiedad (distribución asintótica de la ACF)¶
Si el proceso es ruido blanco (con momentos finitos, en particular ruido blanco gaussiano), entonces para una muestra grande (\(n\to\infty\)), la estimación anterior de la ACF es asintóticamente gaussiana con desvío:
Otra forma de verlo: si es ruido blanco, 95% de las autocorrelaciones (\(h>0\)) estimadas caen a \(\pm \frac{2}{\sqrt{n}}\) de \(0\). Entonces si una medida de autocorrelación cae fuera de este intervalo es porque no proviene de ruido blanco.
Dicho de otro modo, si uno “blanquea” la señal (se queda solo con la parte de ruido), tenemos un test para chequear que lo que obtuvimos sea ruido blanco.
Ejemplo: ruido blanco¶
w = np.random.normal(size=2000)
sm.graphics.tsa.plot_acf(w);
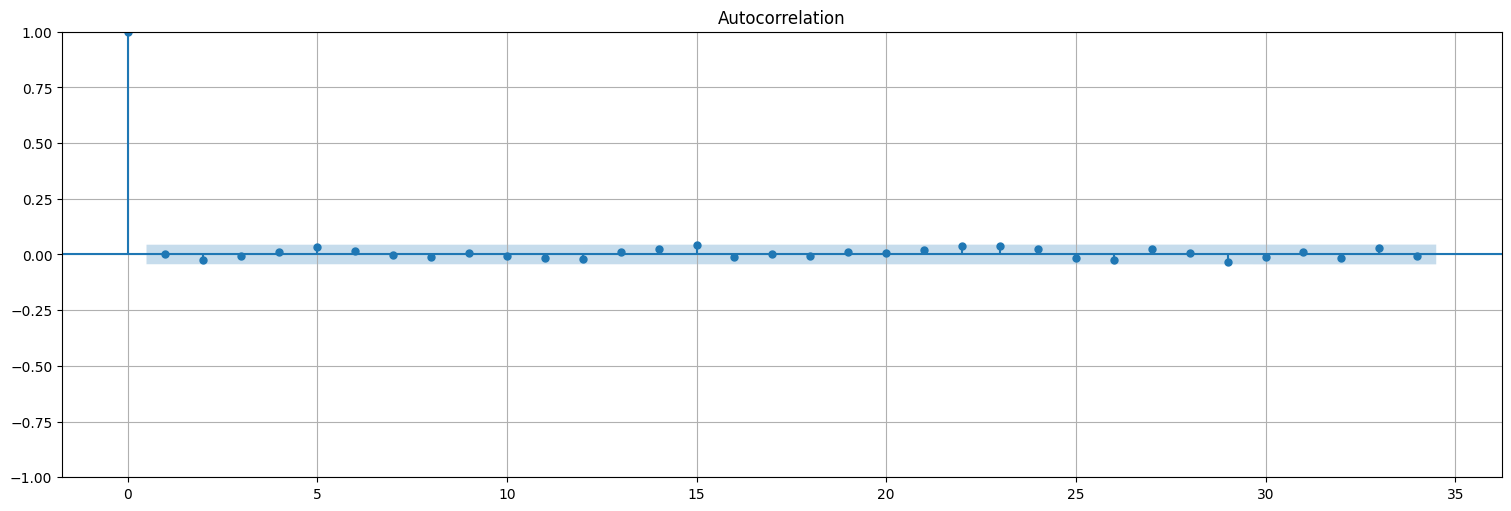
Ejemplo: media móvil¶
Consideremos el proceso: $\(x_t = \frac{1}{3}\left(w_t+w_{t-1}+w_{t-2}\right)\)$
cuya autocorrelación calculamos teóricamente antes.
x = sp.signal.lfilter([1/3,1/3,1/3],[1],w)
sm.graphics.tsa.plot_acf(x);
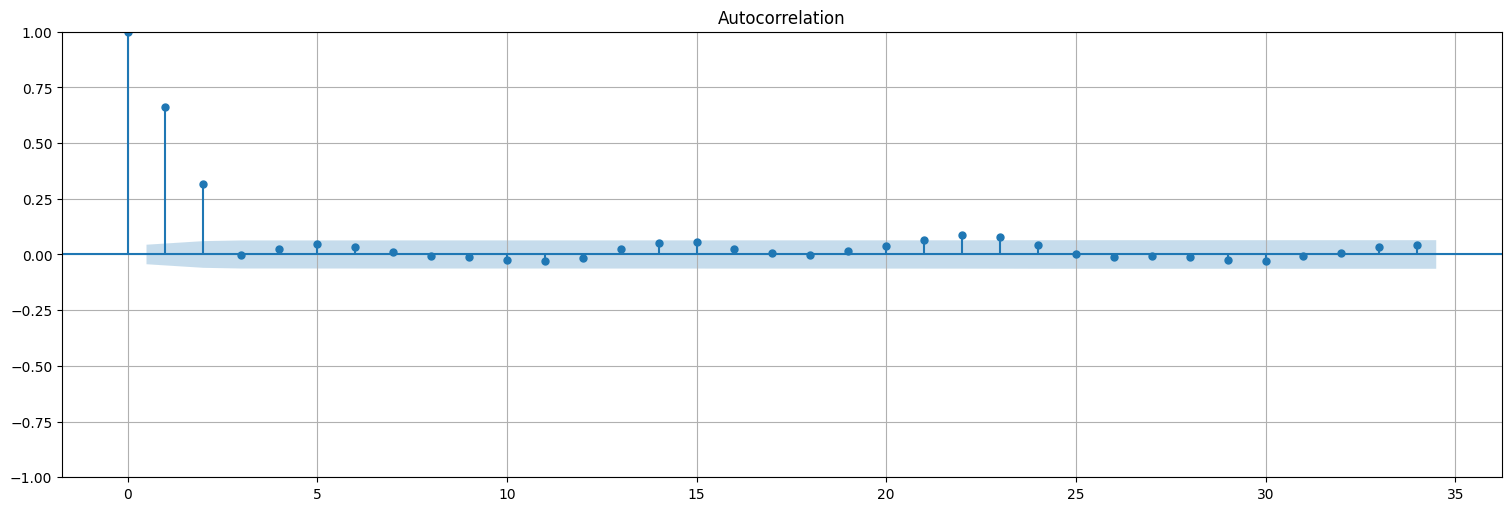
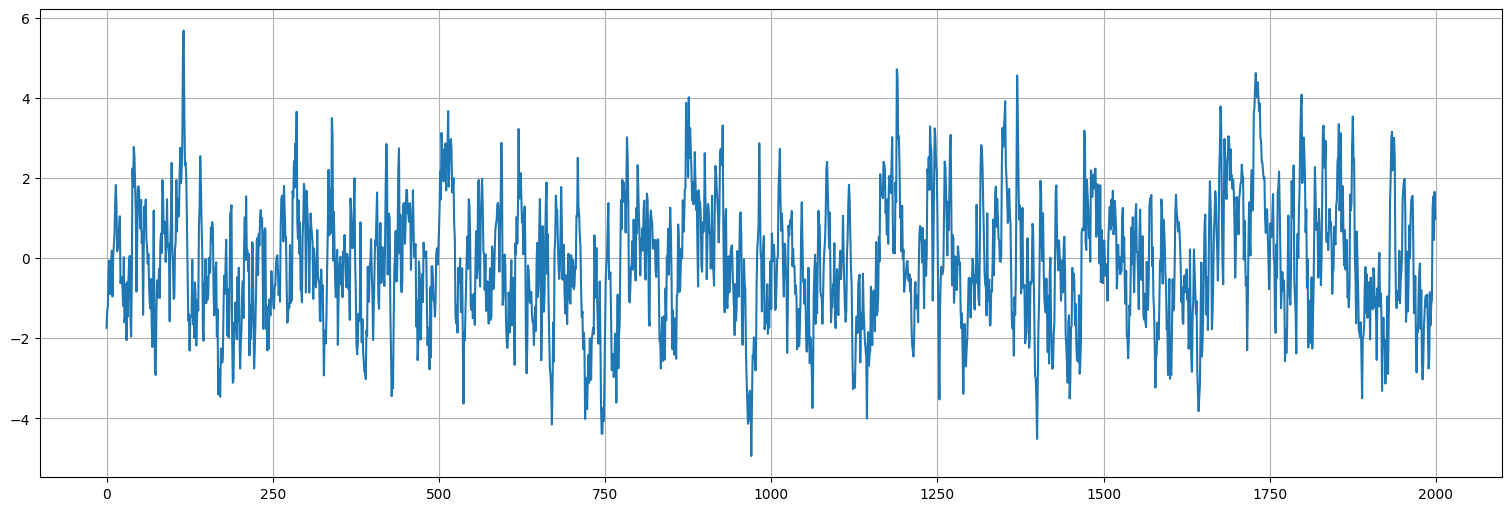
Ejemplo: proceso autorregresivo¶
Consideremos el proceso:
siendo \(w_t\) ruido blanco gaussiano de varianza \(\sigma_w^2=1\).
Simulación¶
#probar cambiar 0.8 por otros valores para ver los cambios. En particular -0.8
x = sp.signal.lfilter([1.0],[1,-.8],w)
plt.plot(x);
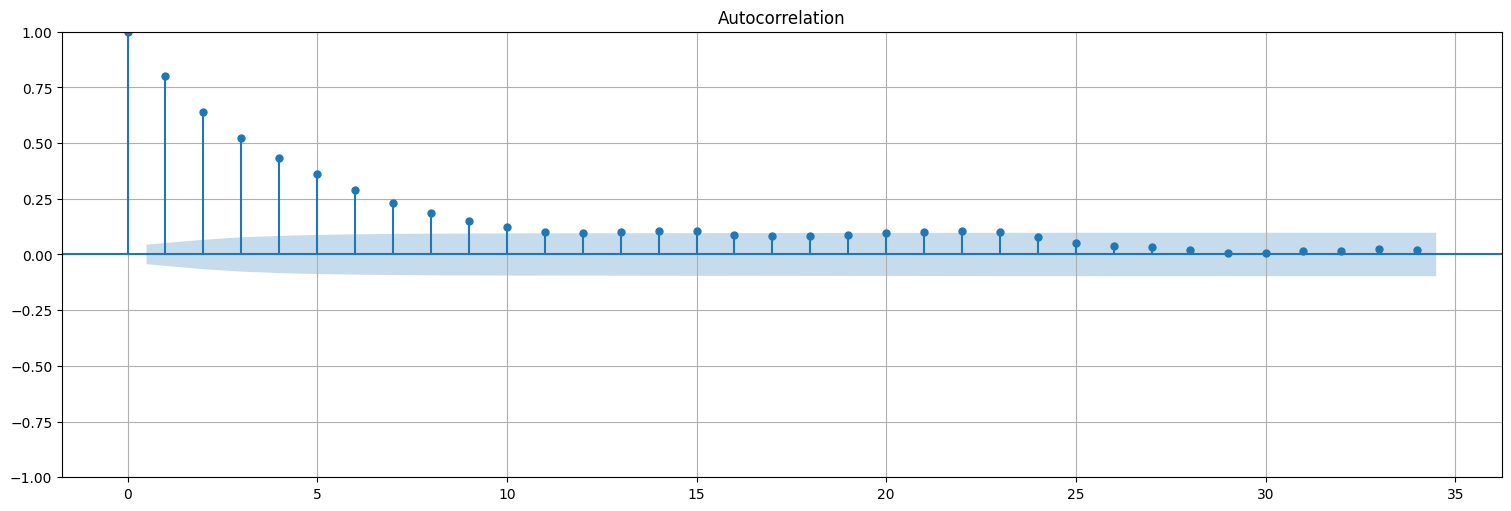
Función de autocorrelación¶
Estimemos la autocorrelación: en un proceso de este tipo, la ACF decae exponencialmente, ya que cada valor depende del anterior, que a su vez depende del anterior, etc. La memoria se va perdiendo con el tiempo.
sm.graphics.tsa.plot_acf(x);
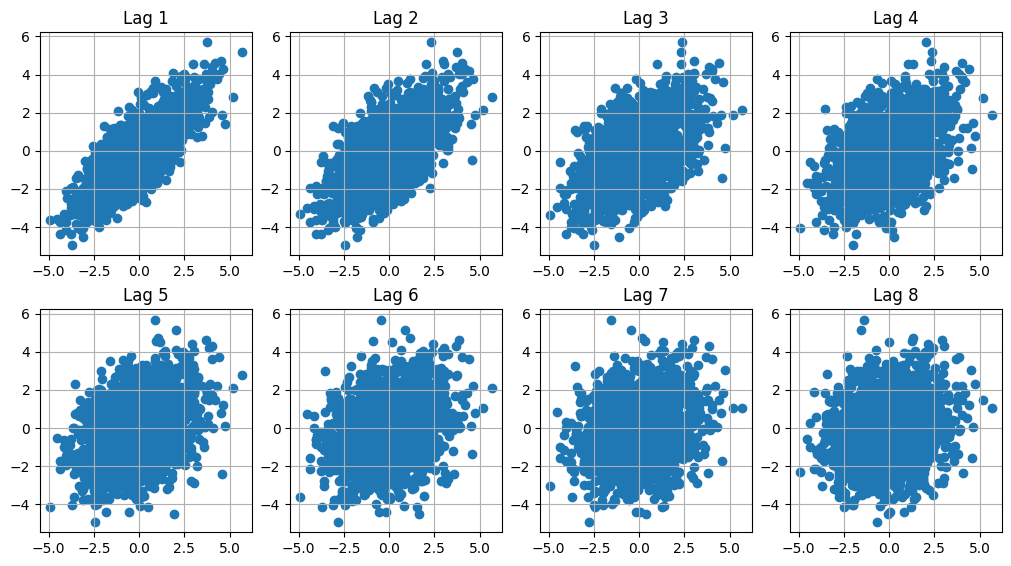
Correlograma con lags¶
Otra forma de entender lo anterior es graficar las parejas \((x_{t-h},x_t)\) en el plano, para diferentes valores del “lag” \(h\). Básicamente la autocorrelación de lag \(h\), \(\hat{\rho}(h)\) es el coeficiente de correlación entre las variables \(x_t\) y \(x_{t-h}\).
plt.figure(figsize=(10,10))
for i in range(1,9):
plt.subplot(4,4,i)
plt.scatter(x,sp.ndimage.shift(x,i));
plt.title(f"Lag {i}")
Ejercicios¶
Ruido blanco vs. media móvil.¶
Simular una señal de ruido blanco y estimar su autocorrelación. Probar con \(n=50\), \(n=200\) y \(n=2000\) datos y discutir las diferencias.
Simular el proceso de media móvil visto anteriormente y estimar su autocorrelación. Probar nuevamente con \(n=50\), \(n=200\) y \(n=2000\) datos y discutir las diferencias.
Simular el proceso autorregresivo visto anteriormente y repetir la pregunta anterior. Discutir las diferencias entre los 3 procesos.
Sugerencia: usar los comandos sp.signal.lfilter y sm.graphics.tsa.plot_acf.
Tendencia lineal más ruido.¶
Consideremos la serie temporal dada por:
con \(\beta_0\) y \(\beta_1\) coeficientes y \(w_t\) es ruido blanco gaussiano de varianza \(\sigma_w^2\).
Simule y grafique \(n=100\) valores de esta serie, tomando \(\beta_0=50\), \(\beta_1=0.2\), \(\sigma^2_w =9\), \(t=(1,\ldots,100)\).
¿La serie es estacionaria?
¿Cómo podría estimar \(\beta_0\) y \(\beta_1\) a partir de las observaciones?
Mostrar que el proceso \(y_t = x_t − x_{t−1}\) es estacionario. ¿Qué media tiene? Utilice el comando
diffpara calcular \(y_t\) y graficarlo. Estimar su autocorrelación.