Modelos lineales¶
El modelo lineal es una herramienta básica de estimación estadística, en particular para estudiar fenómenos causa-efecto y realizar regresión.
En el contexto de series temporales usaremos modelos lineales (y no lineales) con diferentes objetivos:
Obtener información de tendencia y estacionalidad de series.
Ajustar señales de una familia a una observación dada.
Ajustar valores de una serie a una función de los valores anteriores (ej: modelos autorregresivos)
La idea es repasar entonces cómo se realiza el ajuste de modelos lineales y aplicarlo a diferentes series.
Regresión lineal en el contexto de series temporales.¶
Sea \(\{x_t\}\), \(t=1,\ldots,n\) una serie temporal. Queremos explicar su comportamiento a partir de variables independientes \(z_{t_1},\ldots,z_{t_q}\) donde \(q\) es la cantidad de variables explicativas en cada \(t\).
Nota: En la regresión clásica estas variables son completamente independientes, pero en series temporales luego veremos como relajar esto.
Se tiene entonces el Modelo de Regresión Lineal:
\(\beta_1\ldots\beta_q\) son los parámetros a ajustar
\(z_{t_i}\) son las funciones de regresión a usar (a veces llamadas “features”), evaluadas en cada \(t\).
\(w_t\) es ruido blanco (gaussiano) de varianza \(\sigma_w^2\).
Ejemplo: estimación de una tendencia lineal¶
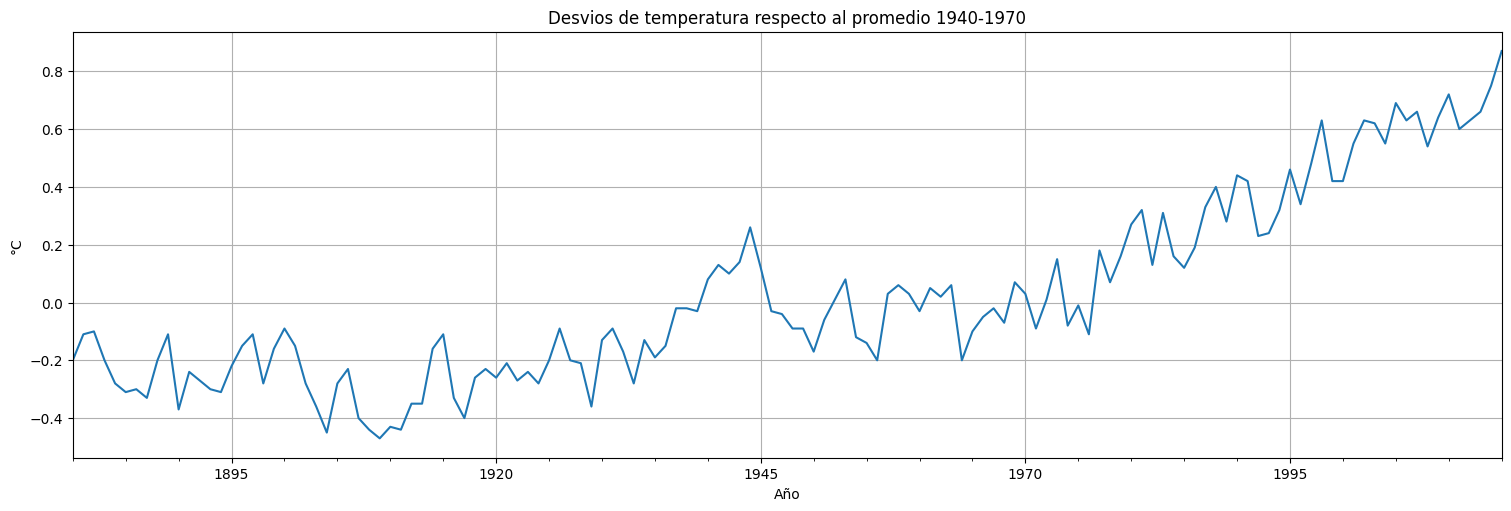
Consideremos los datos de temperatura globtemp disponibles en la biblioteca astsa. Al parecer estos datos tienen una tendencia creciente. Podemos usar un modelo lineal del tipo:
Aquí \(z_{t_1} = 1\) para todo \(t\) y \(z_{t_2} = t\). Tenemos dos parámetros (\(q=2\)) más la varianza del ruido o residuo \(\sigma_w^2\).
#para mirar los datos
globtemp = astsa.globtemp
globtemp.head()
| value | |
|---|---|
| index | |
| 1880 | -0.20 |
| 1881 | -0.11 |
| 1882 | -0.10 |
| 1883 | -0.20 |
| 1884 | -0.28 |
globtemp.plot(legend=False);
plt.title("Desvios de temperatura respecto al promedio 1940-1970")
plt.ylabel("°C")
plt.xlabel("Año");
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
#Extraigo la serie de años del índice de globtemp
time = pd.Series(globtemp.index.year, index=globtemp.index)
time = time - 1880 #elijo como año 0 el comienzo de la serie
#construyo un dataframe que tenga el tiempo en años y las temperaturas
data_reg = pd.concat([time, globtemp], axis=1)
data_reg.columns = ["time", "globtemp"]
#realizo el ajuste del modelo lineal por mínimos cuadrados
fit = ols(formula="globtemp ~ time", data=data_reg).fit()
fit.summary()
| Dep. Variable: | globtemp | R-squared: | 0.752 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.750 |
| Method: | Least Squares | F-statistic: | 406.6 |
| Date: | Mon, 19 May 2025 | Prob (F-statistic): | 2.05e-42 |
| Time: | 15:39:18 | Log-Likelihood: | 58.476 |
| No. Observations: | 136 | AIC: | -113.0 |
| Df Residuals: | 134 | BIC: | -107.1 |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -0.4531 | 0.027 | -16.751 | 0.000 | -0.507 | -0.400 |
| time | 0.0070 | 0.000 | 20.165 | 0.000 | 0.006 | 0.008 |
| Omnibus: | 6.530 | Durbin-Watson: | 0.472 |
|---|---|---|---|
| Prob(Omnibus): | 0.038 | Jarque-Bera (JB): | 3.572 |
| Skew: | 0.173 | Prob(JB): | 0.168 |
| Kurtosis: | 2.286 | Cond. No. | 155. |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
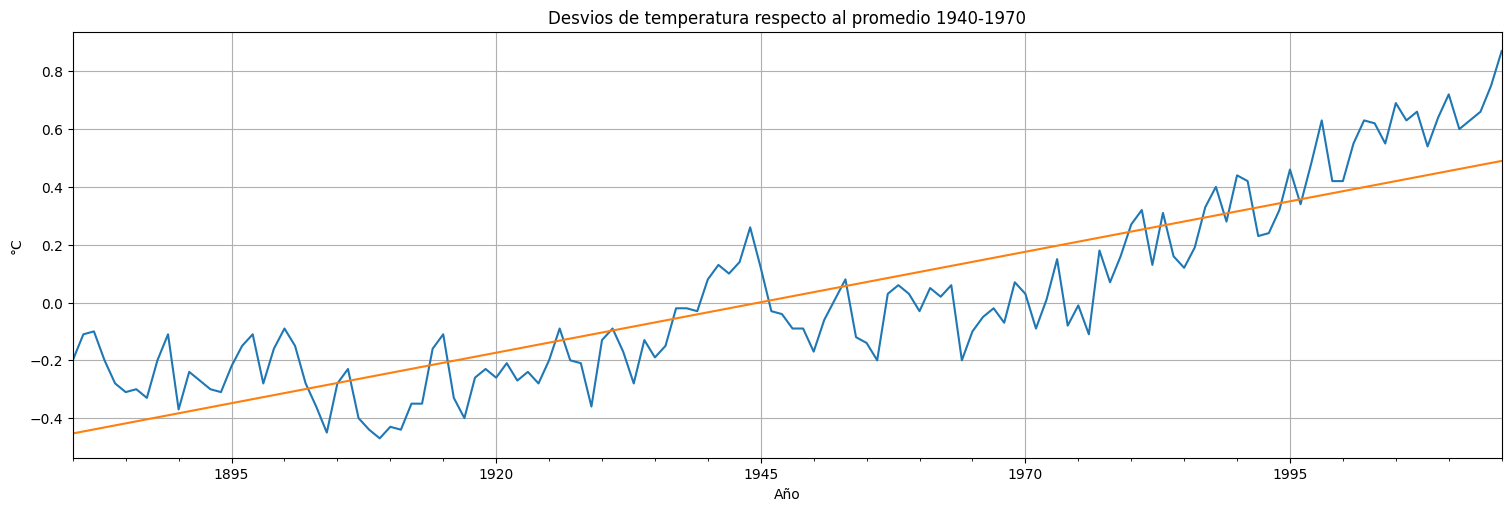
ax = globtemp.plot(xlabel="Time", ylabel="Temp deviation", legend=False)
ax.plot(fit.fittedvalues)
plt.title("Desvios de temperatura respecto al promedio 1940-1970")
plt.ylabel("°C")
plt.xlabel("Año");
¿Cómo funciona?
Conviene pasarse a notación vectorial, sean los vectores columna:
Entonces el valor en \(t\) de la serie puede calcularse como:
(producto escalar de los vectores \(\beta\) y \(z_t\) más el ruido)
Pregunta: ¿Cómo podemos estimar \(\beta\)?
Criterio de mínimos cuadrados¶
Se trata de minimizar la suma de los errores de predicción al cuadrado sobre todos los datos:
La minimización se hace en las variables \(\beta_i\). El óptimo se denota \(\hat{\beta}\), el estimador por mínimos cuadrados del modelo.
Observación: la minimización anterior tiene fórmula exacta!
Ecuaciones Normales¶
Derivando la ecuación anterior respecto a cada \(\beta_i\) e imponiendo que las derivadas sean \(0\) (condición de punto estacionario), se llega al siguiente sistema de ecuaciones para hallar \(\hat{\beta}\):
A dicho sistema lineal (de \(q\) incógnitas) se le denominan “ecuaciones normales”.
Versión matricial¶
Se puede simplificar aún más la notación definiendo la matriz:
que tiene como columnas el valor de la función \(z_{t_n}\) en cada \(t\). Si \(x=(x_1,\ldots,x_t)\) las ecuaciones normales quedan:
y la solución explícita es:
Esto vale siempre que la matriz \((Z^T Z)\) sea invertible (en general si no lo es formulamos mal el modelo)
Ejemplo: ajuste lineal¶
Para el caso de un ajuste lineal: $\(x_t = \beta_1 + \beta_2 t + w_t\)\( La matrix \)Z$ en este caso es:
siendo \(t_i\) los tiempos de la muestra de la serie (ej: el año en globtemp).
Error cometido y Mean Square Error¶
El error cometido en la aproximación es simplemente la suma de los cuadrados:
El estimador \(\hat{\beta}\) de mínimos cuadrados es insesgado, y si los errores son Gaussianos, es el estimador de máxima verosimilitud. En dicho caso podemos calcular la distribución esperada del estimador, la cual resulta una gaussiana de matriz de covarianzas, que permite calcular intervalos de confianza:
El Error Cuadrático Medio (MSE) es simplemente:
y es un estimador insesgado para \(\sigma_w^2\), la varianza del error.
¿Cómo podemos ver si el ajuste fue bueno?¶
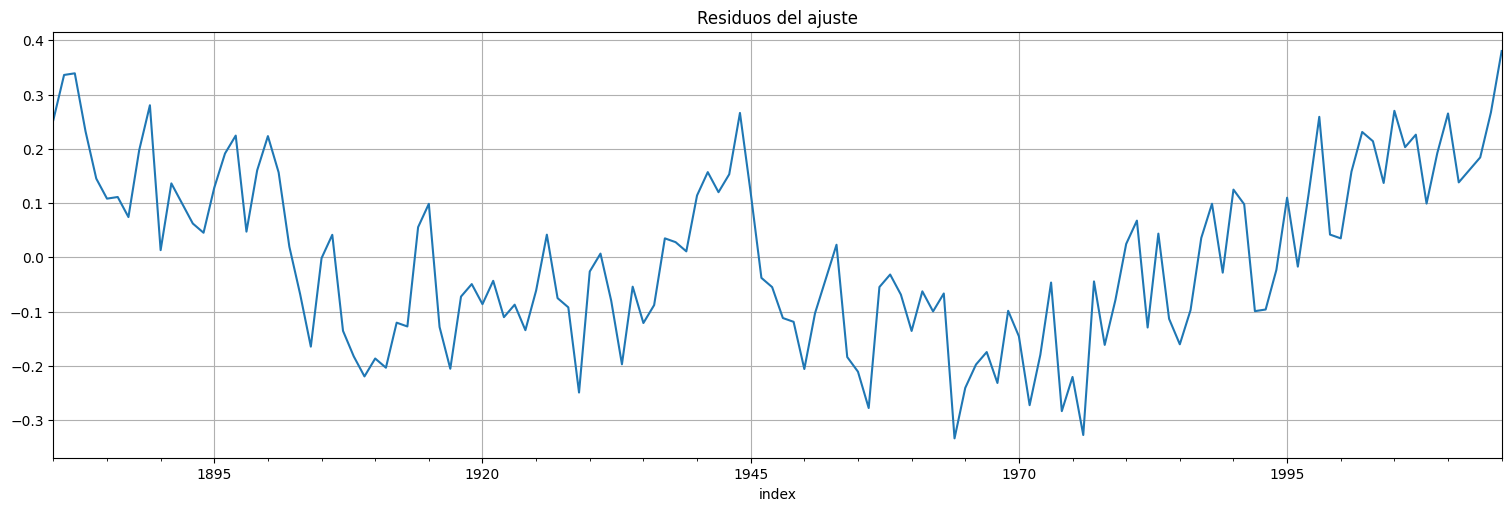
Plotear los residuos. Deberían tener un comportamiento homogéneo.
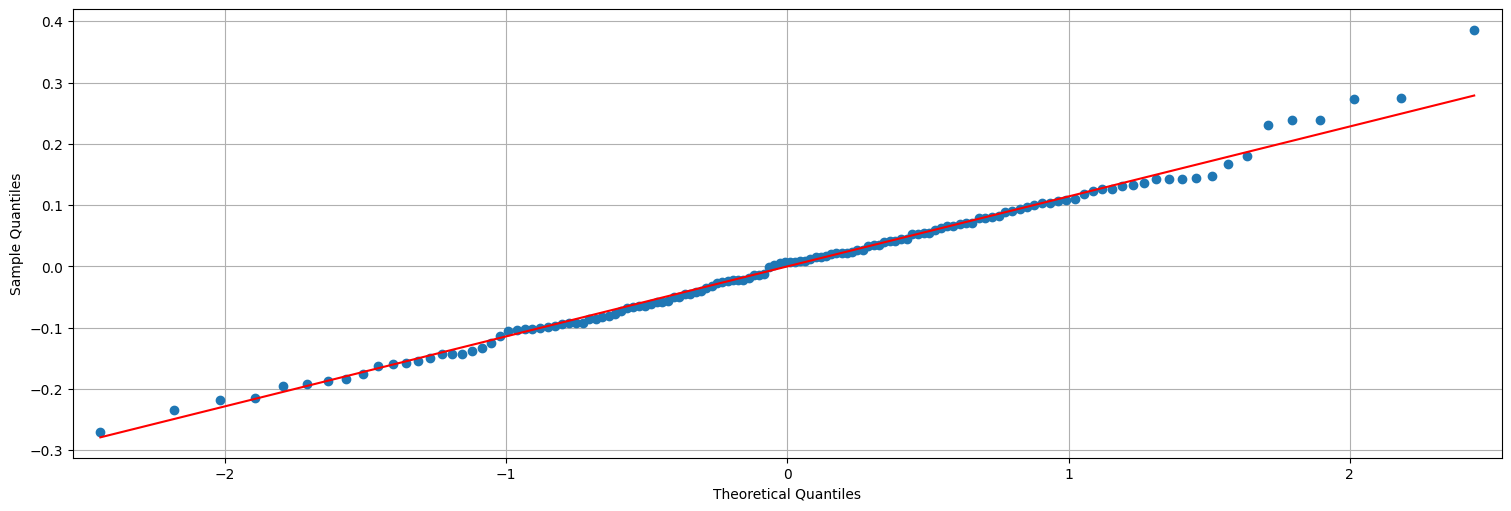
Mirar si los residuos son gaussianos (
qqplot). Esto no es necesario pero si lo son nos ajustamos al modelo anterior perfectamente.Mirar si los residuos son “ruido blanco”. Esta es una regla general: si luego de aplicar un modelo lo que queda es “ruido” es que logramos extraer toda la información.
Mirar si los mejoramos el ajuste respecto a algo simple (por ejemplo, la media) \(\to\) Criterio \(R^2\)
Observar que no hubo sobreajuste (overfitting). Esto puede pasar si tengo demasiados parámetros. \(\to\) Criterio de información (\(AIC\), \(BIC\)).
residuos = fit.resid
residuos.plot();
plt.title("Residuos del ajuste");
## QQ-plot es una verificación de gaussianidad.
sm.qqplot(residuos, line="s");
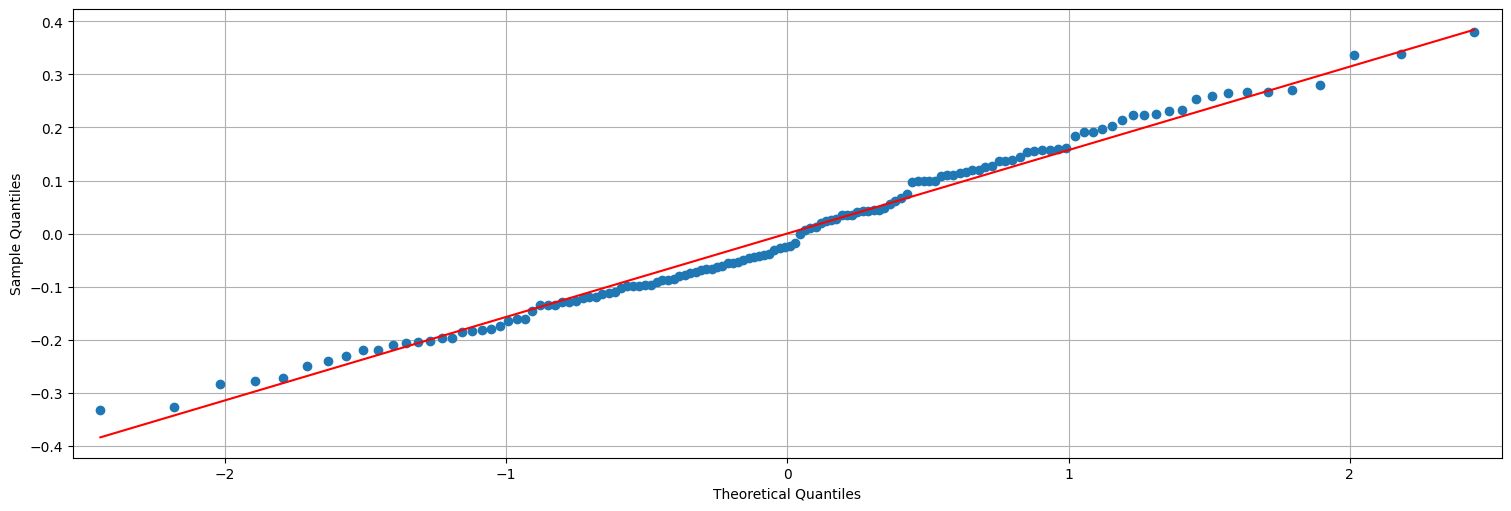
Nota:¶
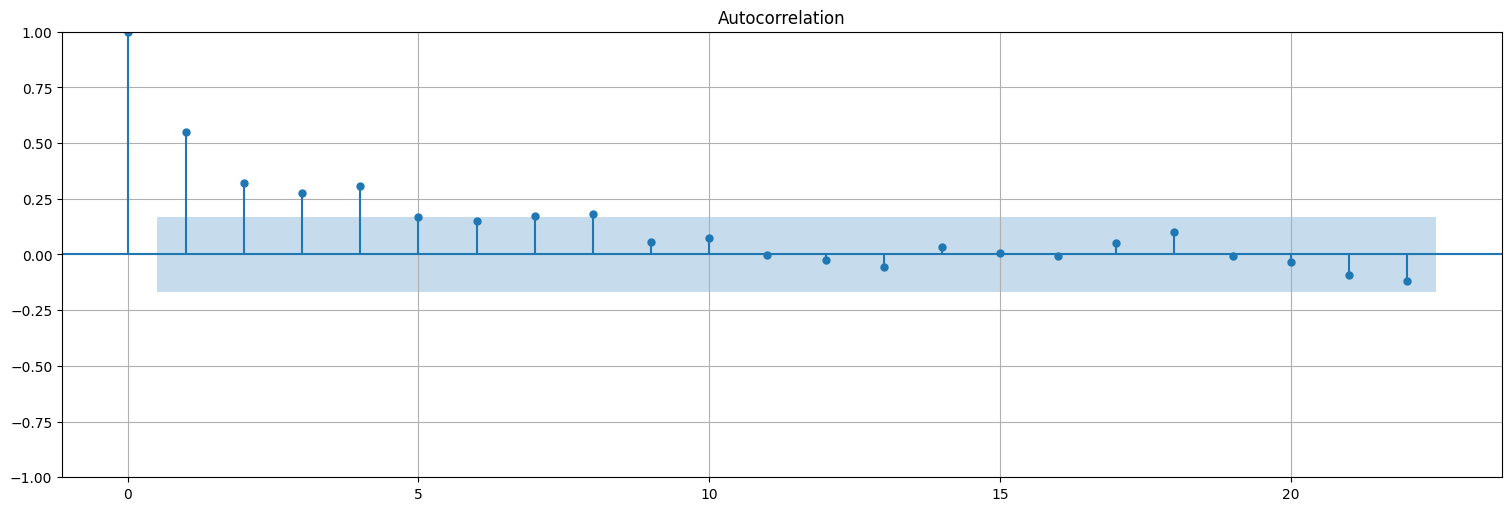
Para calcular la acf, conviene utilizar statsmodels.tsa.graphics.plot_acf() con la opción bartlett_confint=False para usar el intervalo de confianza correcto
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(residuos, bartlett_confint=False);
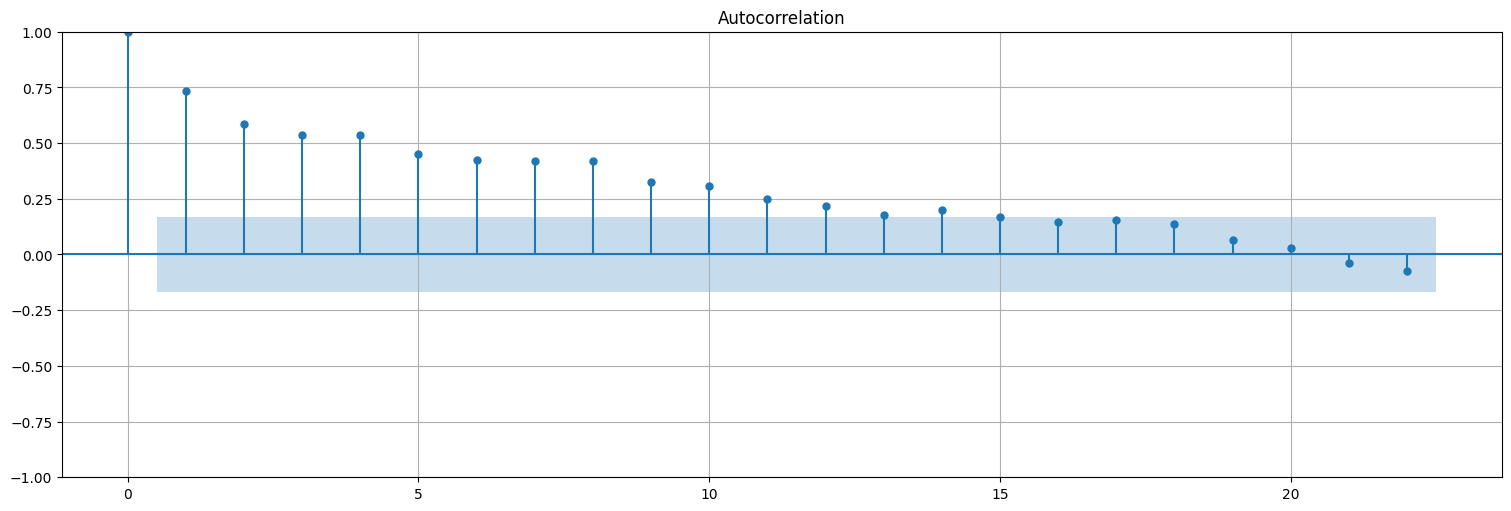
Nota: Los residuos no quedan ruido blanco. Es decir que estrictamente no estamos en las hipótesis del modelo lineal. Más adelante veremos cómo mejorar esto.
Evaluación:¶
Deseamos evaluar si mejoramos el ajuste respecto a algo simple. El modelo lineal más simple es:
Es decir, media más ruido. En este caso, la solución es \(\hat{\beta}_1 = \bar{x}\), la media de los datos, y el error cuadrático \(SSE_1\) es:
Definimos:
Entonces \(R^2\) es una medida de correlación de nuestras variables \(z\) con \(x\), o bien cuánto mejora el ajuste en términos relativos respecto a la media.
SSE1 = np.sum((globtemp.values-np.mean(globtemp.values))**2, axis=0)
SSE = np.sum(fit.resid**2)
MSE = SSE/(globtemp.size - 2)
RMSE = np.sqrt(MSE)
R2 = (SSE1-SSE)/SSE1
#muestro los valores
print(f"SSE1: {SSE1}")
print(f"SSE: {SSE}")
print(f"MSE: {MSE}")
print(f"RMSE: {RMSE}")
print(f"R2: {R2}")
SSE1: [13.59504412]
SSE: 3.3697434158675637
MSE: 0.025147338924384803
RMSE: 0.15857912512176628
R2: [0.75213443]
Comparemos con el resumen del ajuste anterior:
fit.summary()
| Dep. Variable: | globtemp | R-squared: | 0.752 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.750 |
| Method: | Least Squares | F-statistic: | 406.6 |
| Date: | Mon, 19 May 2025 | Prob (F-statistic): | 2.05e-42 |
| Time: | 15:39:22 | Log-Likelihood: | 58.476 |
| No. Observations: | 136 | AIC: | -113.0 |
| Df Residuals: | 134 | BIC: | -107.1 |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -0.4531 | 0.027 | -16.751 | 0.000 | -0.507 | -0.400 |
| time | 0.0070 | 0.000 | 20.165 | 0.000 | 0.006 | 0.008 |
| Omnibus: | 6.530 | Durbin-Watson: | 0.472 |
|---|---|---|---|
| Prob(Omnibus): | 0.038 | Jarque-Bera (JB): | 3.572 |
| Skew: | 0.173 | Prob(JB): | 0.168 |
| Kurtosis: | 2.286 | Cond. No. | 155. |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Modelos lineales más complejos¶
Observemos que el modelo lineal general:
nada dice que la aproximación tenga que ser por una recta. De hecho es bastante general. Eligiendo los \(z_{t_i}\) podemos hacer ajustes más complicados. La razón por la que se llama lineal es que los pesos \(\beta_i\) entran linealmente en la ecuación, y admiten entonces resolverse por ecuaciones normales.
Ejemplo: ajustar una tendencia cuadrática a las temperaturas.¶
Es simplemente considerar:
Aquí \(z_{t_1} = 1\) para todo \(t\), \(z_{t_2} = t\) y \(z_{t_3} = t^2\). Tenemos tres parámetros (\(q=3\))
time2 = time**2
data_reg = pd.concat([time, time2, globtemp], axis=1)
data_reg.columns = ["time", "time2", "globtemp"]
fit2 = ols(formula="globtemp ~ time + time2", data=data_reg).fit()
fit2.summary()
| Dep. Variable: | globtemp | R-squared: | 0.870 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.868 |
| Method: | Least Squares | F-statistic: | 443.3 |
| Date: | Mon, 19 May 2025 | Prob (F-statistic): | 1.49e-59 |
| Time: | 15:39:22 | Log-Likelihood: | 102.13 |
| No. Observations: | 136 | AIC: | -198.3 |
| Df Residuals: | 133 | BIC: | -189.5 |
| Df Model: | 2 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -0.2161 | 0.029 | -7.382 | 0.000 | -0.274 | -0.158 |
| time | -0.0036 | 0.001 | -3.620 | 0.000 | -0.006 | -0.002 |
| time2 | 7.86e-05 | 7.18e-06 | 10.943 | 0.000 | 6.44e-05 | 9.28e-05 |
| Omnibus: | 2.664 | Durbin-Watson: | 0.892 |
|---|---|---|---|
| Prob(Omnibus): | 0.264 | Jarque-Bera (JB): | 2.155 |
| Skew: | 0.275 | Prob(JB): | 0.340 |
| Kurtosis: | 3.278 | Cond. No. | 2.42e+04 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 2.42e+04. This might indicate that there are
strong multicollinearity or other numerical problems.
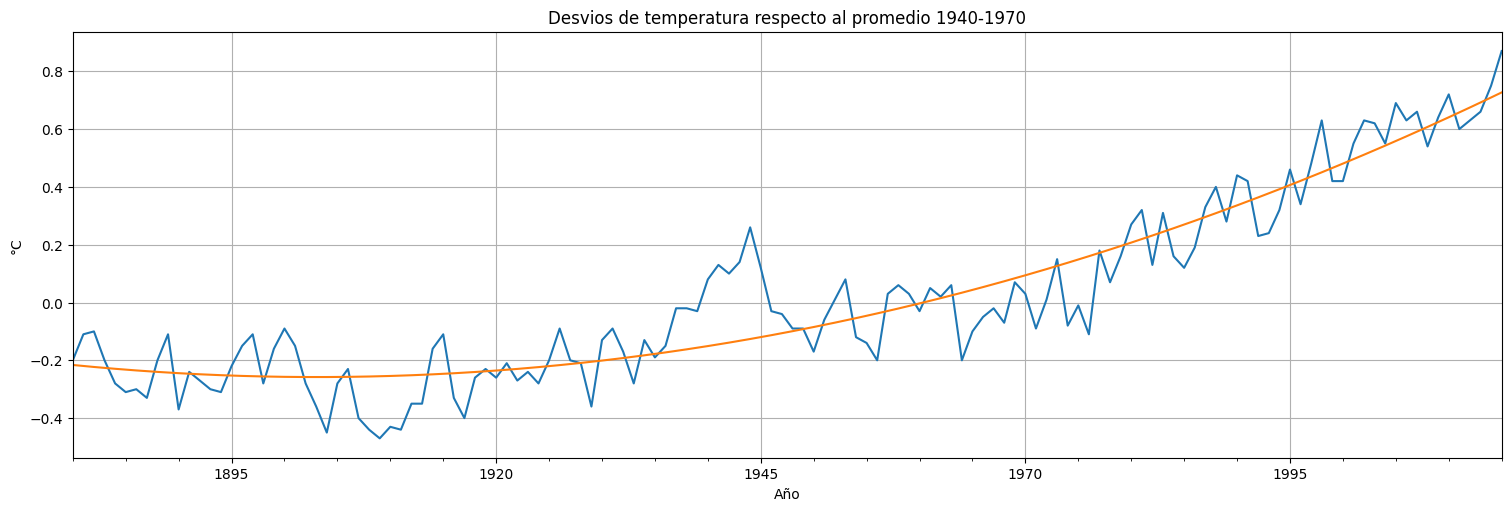
ax = globtemp.plot(xlabel="Time", ylabel="Temp deviation", legend=False)
ax.plot(fit2.fittedvalues)
plt.title("Desvios de temperatura respecto al promedio 1940-1970")
plt.ylabel("°C")
plt.xlabel("Año");
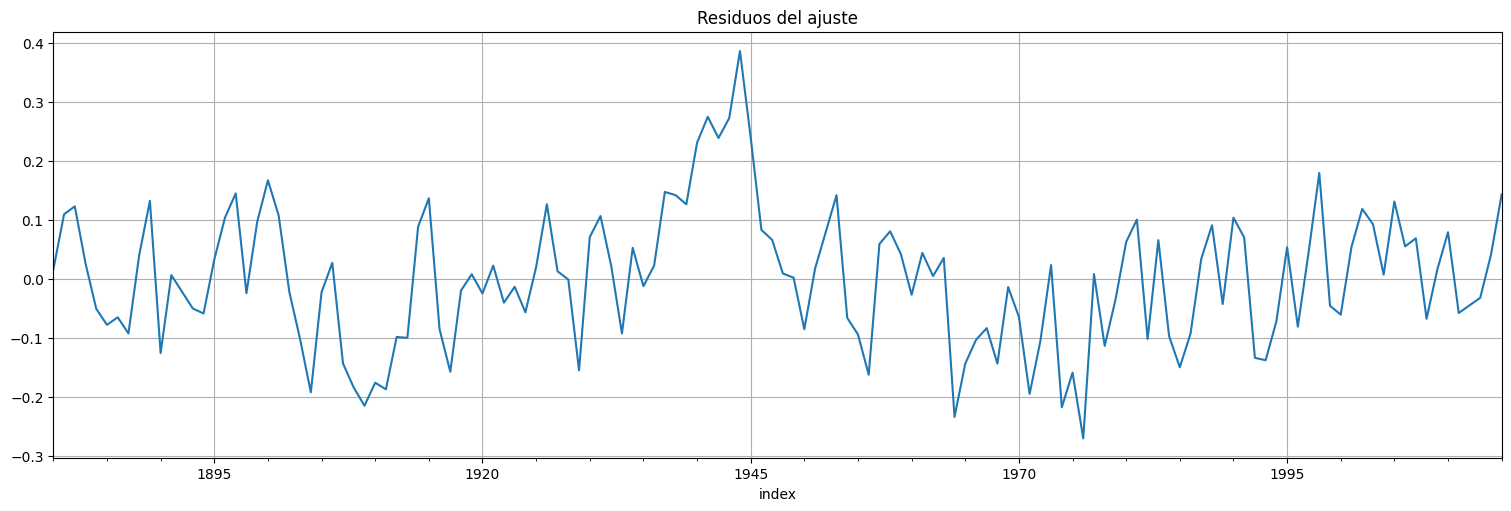
res2 = fit2.resid
res2.plot();
plt.title("Residuos del ajuste");
## QQ-plot es una verificación de gaussianidad.
sm.qqplot(res2, line="s");
plot_acf(res2, bartlett_confint=False);
SSE1 = np.sum((globtemp.values-np.mean(globtemp.values))**2, axis=0)
SSE = np.sum(res2**2)
MSE = SSE/(globtemp.size - 3)
RMSE = np.sqrt(MSE)
R2 = (SSE1-SSE)/SSE1
#muestro los valores
print(f"SSE1: {SSE1}")
print(f"SSE: {SSE}")
print(f"MSE: {MSE}")
print(f"RMSE: {RMSE}")
print(f"R2: {R2}")
SSE1: [13.59504412]
SSE: 1.773245881876174
MSE: 0.013332675803580257
RMSE: 0.11546720661547268
R2: [0.86956674]
Akaike information criterion¶
Es una herramienta para selección de modelos. La idea es ponderar en parte la verosimilitud del modelo (calidad del ajuste) con la cantidad de parámetros involucrados (para prevenir el overfitting).
Definición (Akaike Information Criterion): Se define el AIC de un ajuste como:
\[AIC = -2\log \hat{L}_q + 2q.\]siendo \(\hat{L}_q\) la log-verosimilitud. Cuanto más pequeño el AIC mejor.
En el caso de ajuste lineal con residuos gaussianos, la (log-)verosimilitud depende de la varianza de los residuos, es decir:
siendo \(q\) la cantidad de parámetros y \(n\) la cantidad de muestras de la serie, como veremos a continuación.
Verosimilitud del modelo¶
La hipótesis del modelo lineal es que los errores respecto al modelo son Gaussianas independientes de varianza \(\sigma_w^2\). La verosimilitud se define entonces como:
es decir, la densidad conjunta de los errores evaluada en los valores observados. A mayor densidad conjunta, más “chance” de que el modelo observado sea correcto (más verosimilitud).
En general conviene trabajar con la log-verosimilitud:
Sustituyendo \(\sigma_w^2\) por el valor estimado \(\hat{\sigma}^2_w = SSE^2_q/n\) se tiene el estimador de la log-verosimilitud \(\log \hat{L}_q\).
Ejemplo:¶
Calculemos el AIC del ajuste lineal guardado en la variable fit:
n=globtemp.size
sigmaw2 = sum(res2**2)/n
logver = -n*np.log(np.sqrt(2*np.pi*sigmaw2)) - sum(res2**2/(2*sigmaw2))
print(f"Verosimilitud del ajuste: {logver}")
Verosimilitud del ajuste: 102.13369620003536
De aquí se deduce el AIC:
q=3 #parámetros estimados: intercept + trend + varianza del ruido
AIC = -2*logver + 2*q
print(f"AIC: {AIC}")
AIC: -198.26739240007072
Bayesian information criterion¶
Es una herramienta análoga a la anterior, que penaliza distinto los parámetros involucrados.
Definición (Bayesian Information Criterion): Se define el BIC de un ajuste como:
\[BIC = -2\log \hat{L}_q + q\log(n)\]
Cuanto más pequeño el BIC mejor. Funciona mejor que el AIC en muestras grandes.
q=3 #parámetros estimados: intercept + trend + varianza del ruido
BIC = -2*logver + q*np.log(n)
print(f"BIC: {BIC}")
BIC: -189.52942774286257
Comparación de ajustes¶
print(f"AIC: Modelo lineal: {fit.aic} | Modelo cuadrático: {fit2.aic}")
print(f"AIC: Modelo lineal: {fit.bic} | Modelo cuadrático: {fit2.bic}")
AIC: Modelo lineal: -112.95200531967131 | Modelo cuadrático: -198.26739240007066
AIC: Modelo lineal: -107.12669554819921 | Modelo cuadrático: -189.5294277428625
Vemos que el \(AIC\) y el \(BIC\) mejoran levemente en el ajuste cuadrático.
Ejercicios¶
Regresión con factores o “dummies”.¶
Consideremos la serie \(y_t\) de ganancias de Johnson & Johnson almacenada en jj. Se realiza la transformación \(x_t = \log(y_t)\). Dicha transformación muestra los incrementos relativos o porcentuales (al pasar a logaritmo).
Ajustar un modelo de la forma: $\( x_t = \beta_0 t + \sum_{i=1}^4 \beta_i Q_i(t) + w_t \)\( siendo \)Q_i\( una función que vale \)1\( si se está en el trimestre \)i\( y \)0$ si no.
Graficar los datos y superponer los datos ajustados.
Calcular los residuos y evaluar el ajuste.
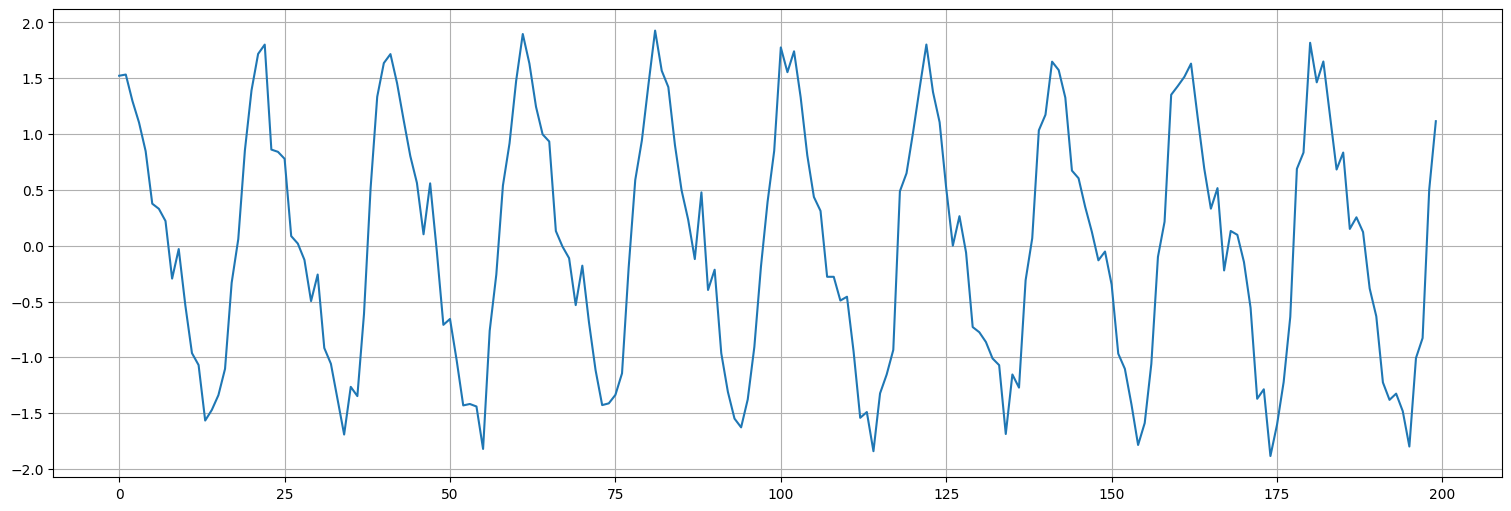
Señal en presencia de ruido.¶
Considere la señal generada más abajo, que consiste en una componente periódica más ruido.
Ajuste un modelo de la forma: $\( x_t = \beta_1 + \beta_2 \cos(2\pi t) + \beta_3 \sin(2\pi t) + w_t. \)$
Ajuste un modelo de la forma: $\( x_t = \beta_1 + \beta_2 \cos(2\pi t) + \beta_3 \sin(2\pi t) + \beta_4 \cos(2\pi 2t) + \beta_5 \sin(2\pi 2t) + w_t. \)$
¿Qué captura este segundo modelo?
Compare los residuos y los ajustes en cada uno.
t = np.arange(0,10,0.05)
s = np.cos(2*np.pi*t) + np.sin(2*np.pi*t) + 0.5*np.cos(2*np.pi*2*t)
w = np.random.normal(size=t.size,loc=0,scale=0.2)
datos = s+w;
plt.plot(datos);